AI
本地运行大模型的方式很多,如:python、ollama、LMStudio等。该篇笔记叙述了如何在本地通过ollama和LMStudio运行大模型,并在知识库中接入ollama或lmstudio
ollama
这是一款快速运行本地大模型的工具
docker部署ollama
用法
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information显示性能参数
--verbose例如
ollama run deepseek-r1:1.5b --verbose>>> 你是什么模型
<think>
</think>
我是一个AI助手,由中国的深度求索(DeepSeek)公司独立开发,我清楚自己的身份与局限,会始终秉持专业和诚实的态度帮助
用户。
total duration: 1.507155093s
load duration: 15.650371ms
prompt eval count: 6 token(s)
prompt eval duration: 35ms
prompt eval rate: 171.43 tokens/s
eval count: 40 token(s)
eval duration: 1.455s
eval rate: 27.49 tokens/s启用gpu
windows
更新NVIDIA驱动之后,使用上面的docker部署ollama中的gpu文件即可
检测是否已安装驱动
nvidia-smi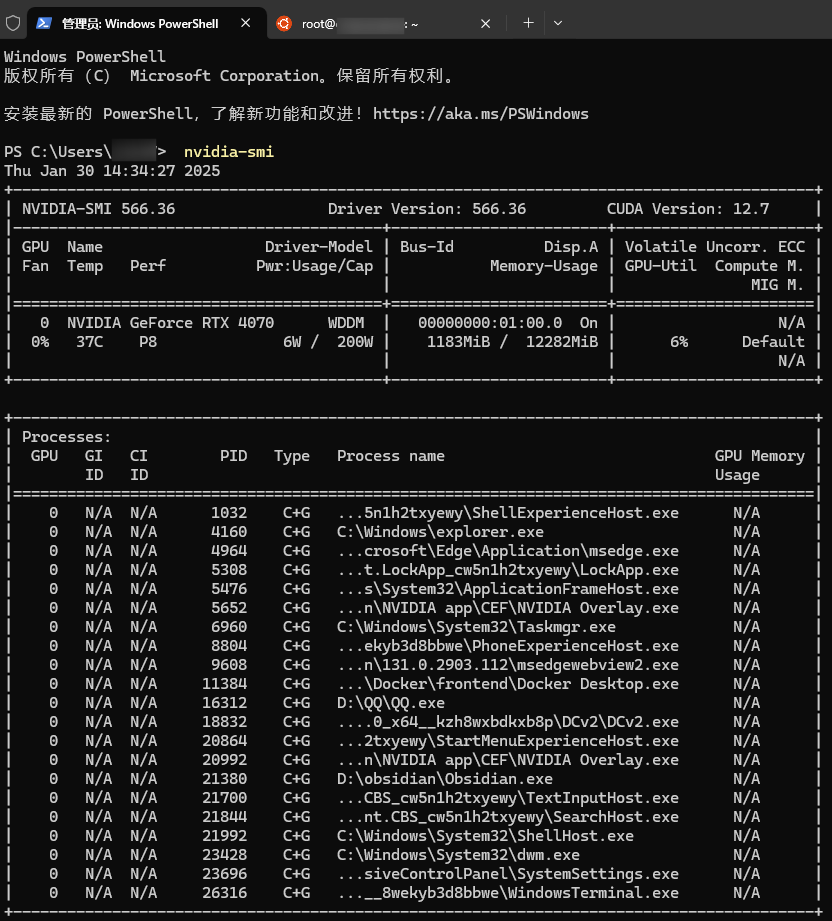
linux
需要先安装NVIDIA开发工具包 Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit
openeular官方安装NVIDIA工具包文档 AI容器镜像用户指南 | openEuler文档 | openEuler社区 | v24.03_LTS_SP1
安装成功后执行这个,查看是否安装成功
nvidia-smi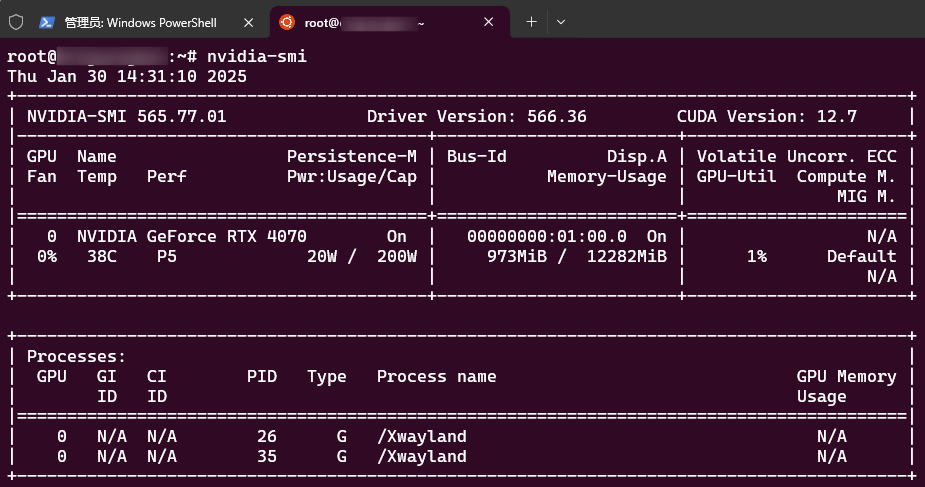
lmstudio
这也是一款本地使用大模型的应用
注意
如需正常使用,下述两点需要满足一点
- 启用tun
- 将lmstudio的huggingface的源换成其他源
使用方式
界面介绍
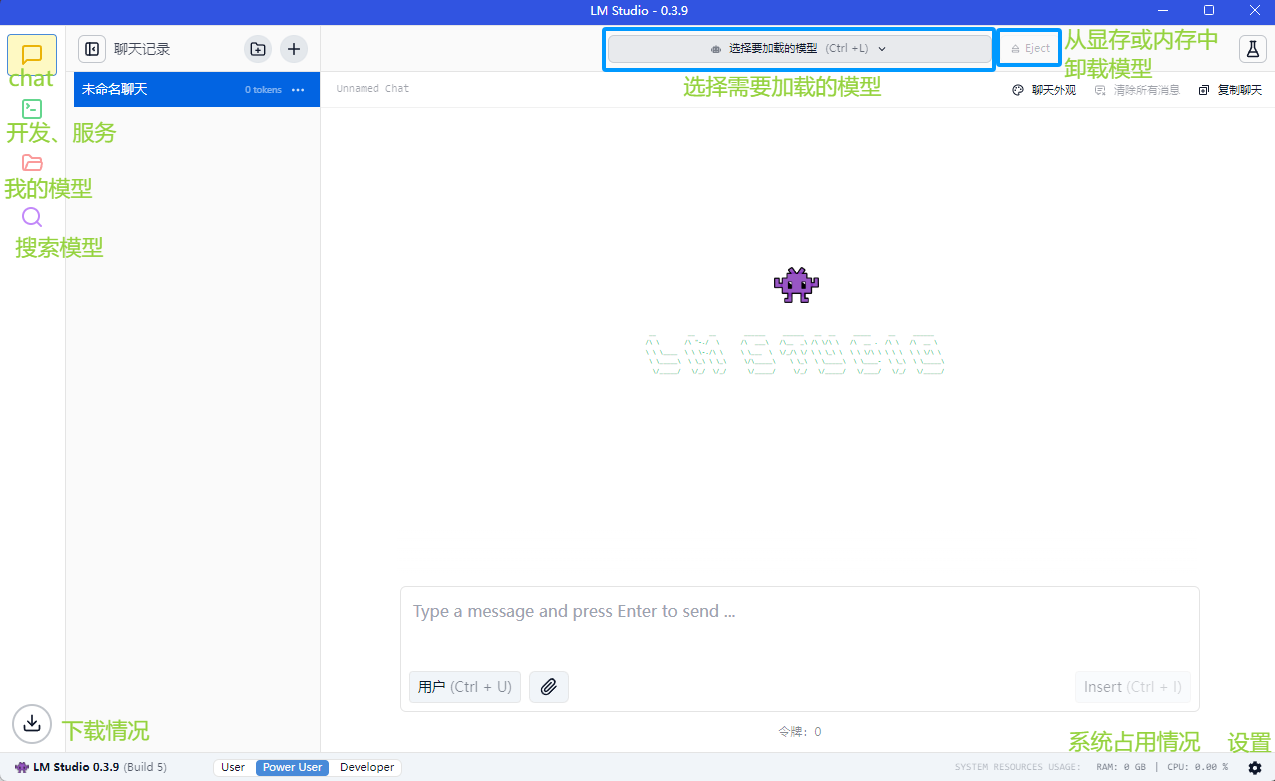
模型加载配置
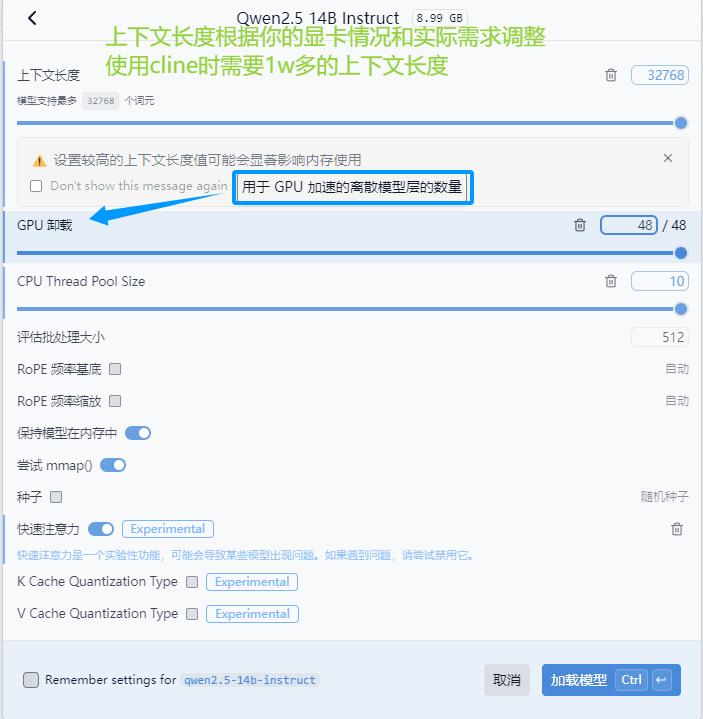
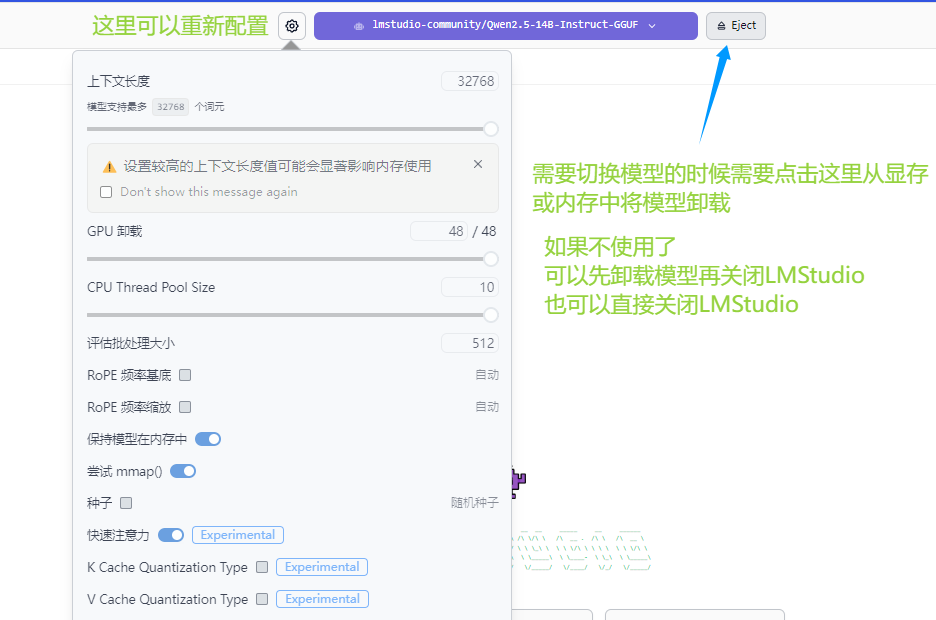
如何修改配置或卸载模型
系统设置
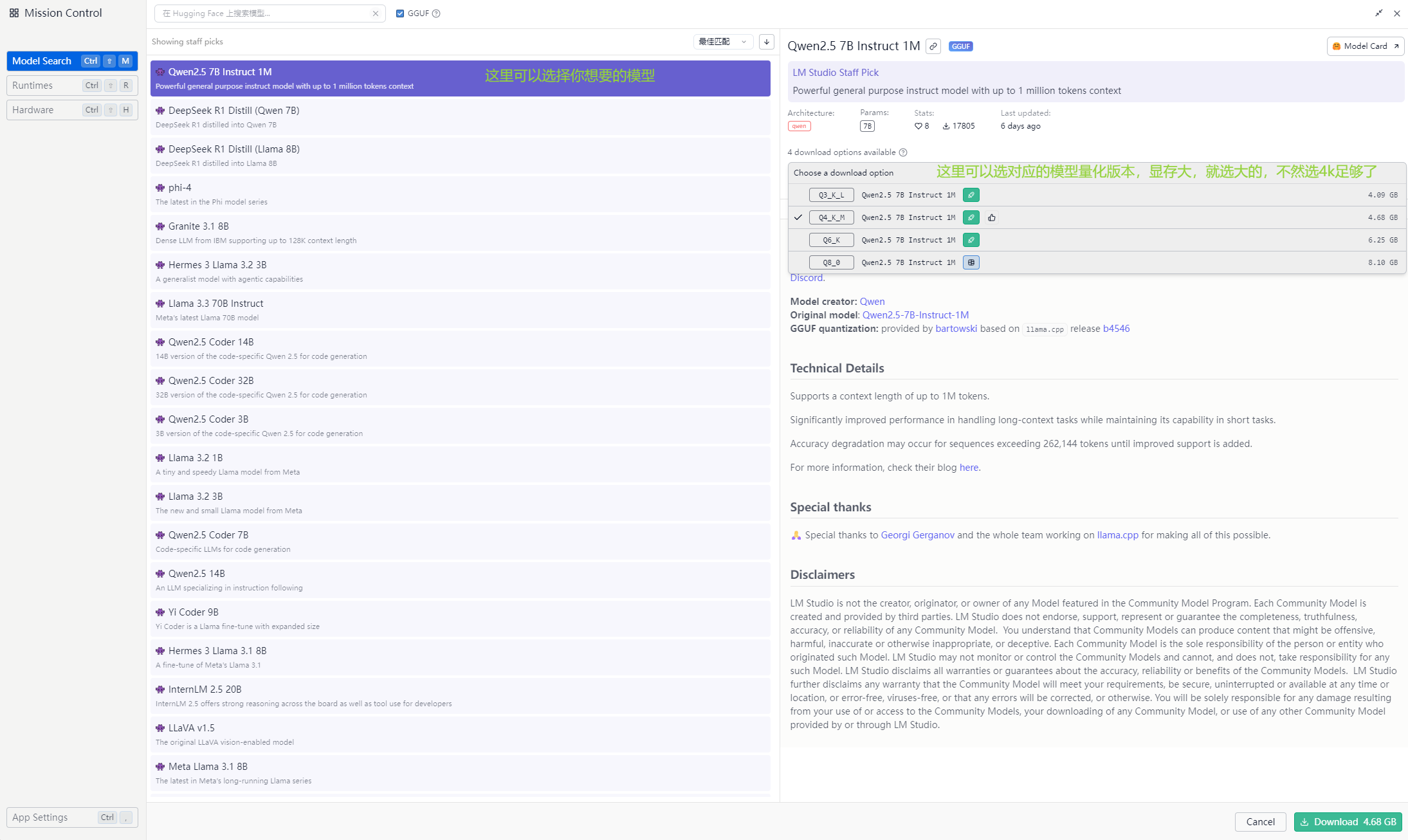
选择并下载模型(启用tun或换源)
选择运行时环境(就是选你要用cpu跑还是用显卡跑)
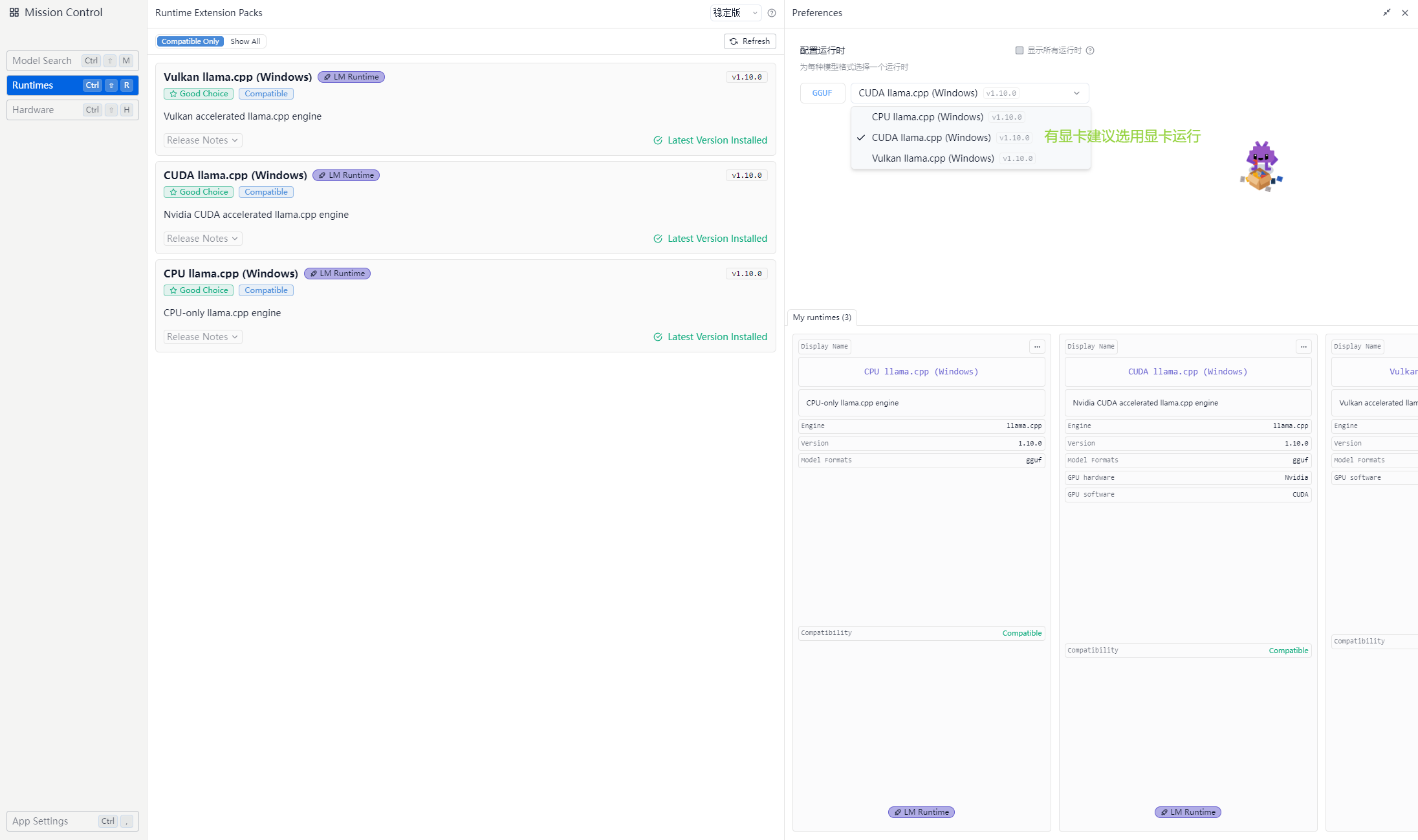
硬件信息
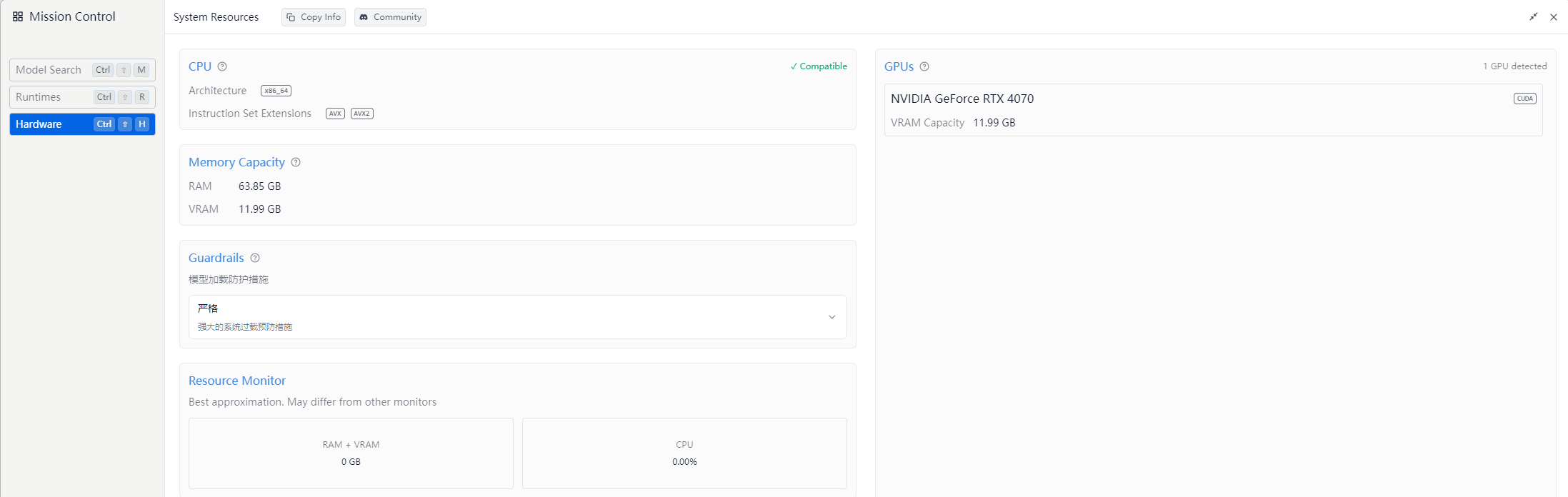
使用情况
注意
下面案例为4070显卡跑模型的实际运行情况,驱动版本为:566.36;选择下载驱动
qwen2.5:14b的运行情况(能接受)
更新驱动到572.16后,速度变慢了,nv负更新石锤
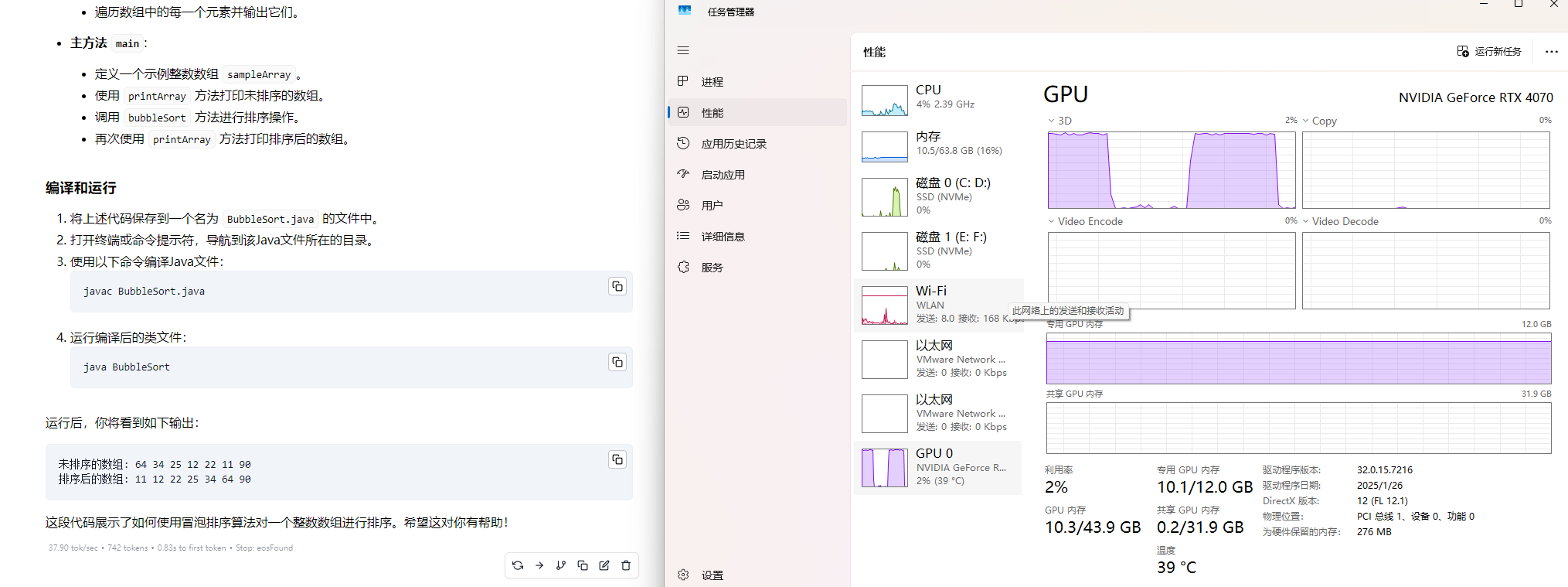
qwen2.5:32b的运行情况(特别慢)
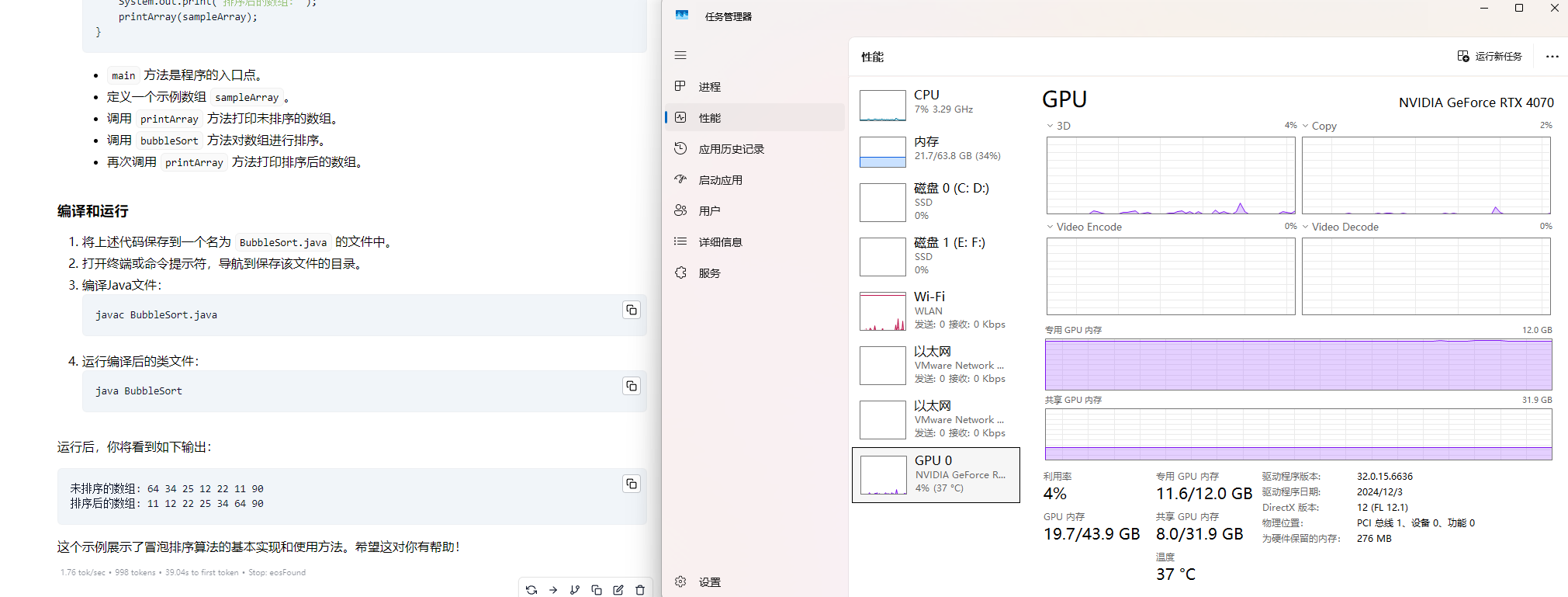
cline代码辅助工具测试(挺好)
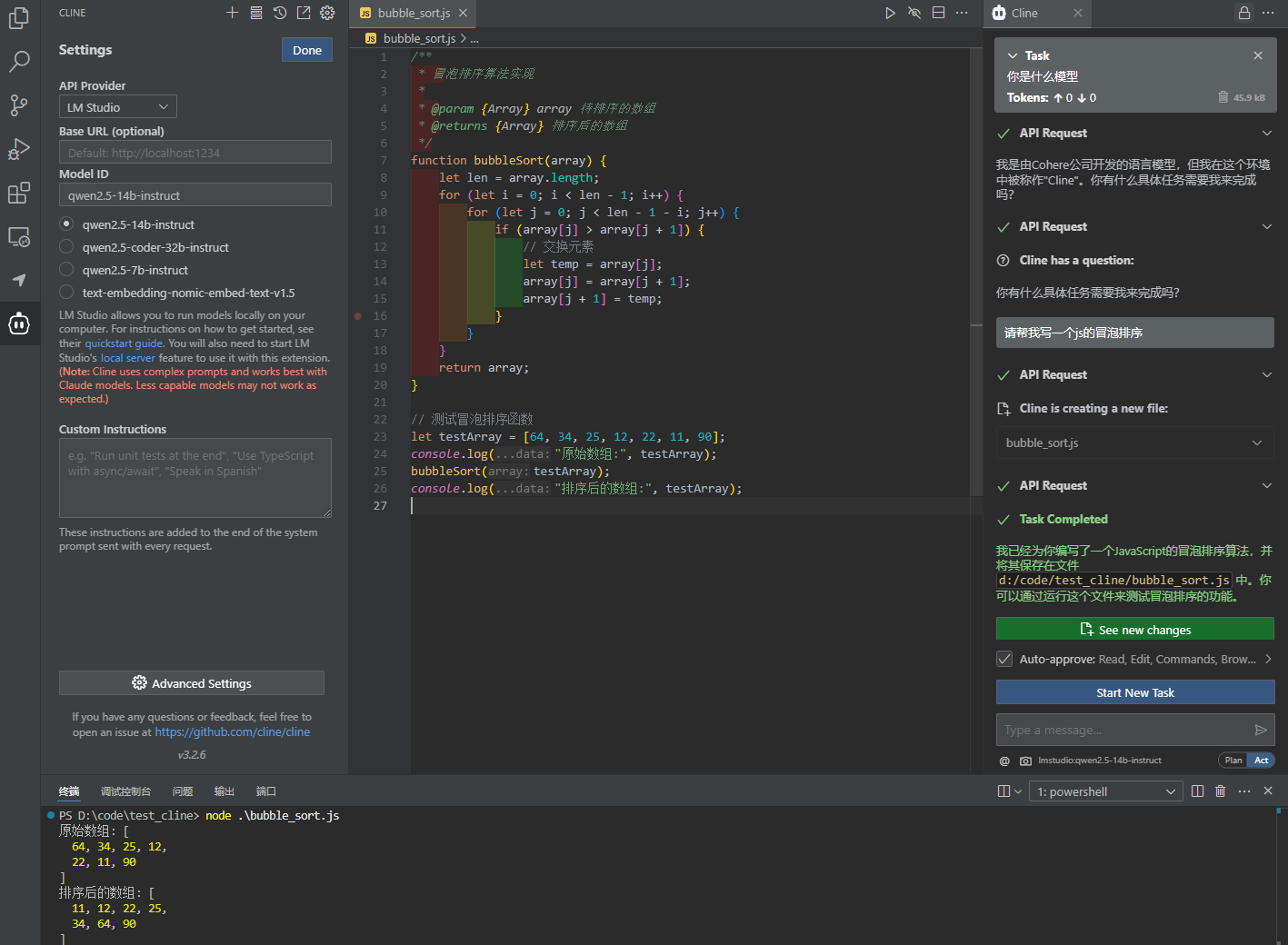
使用openwebui
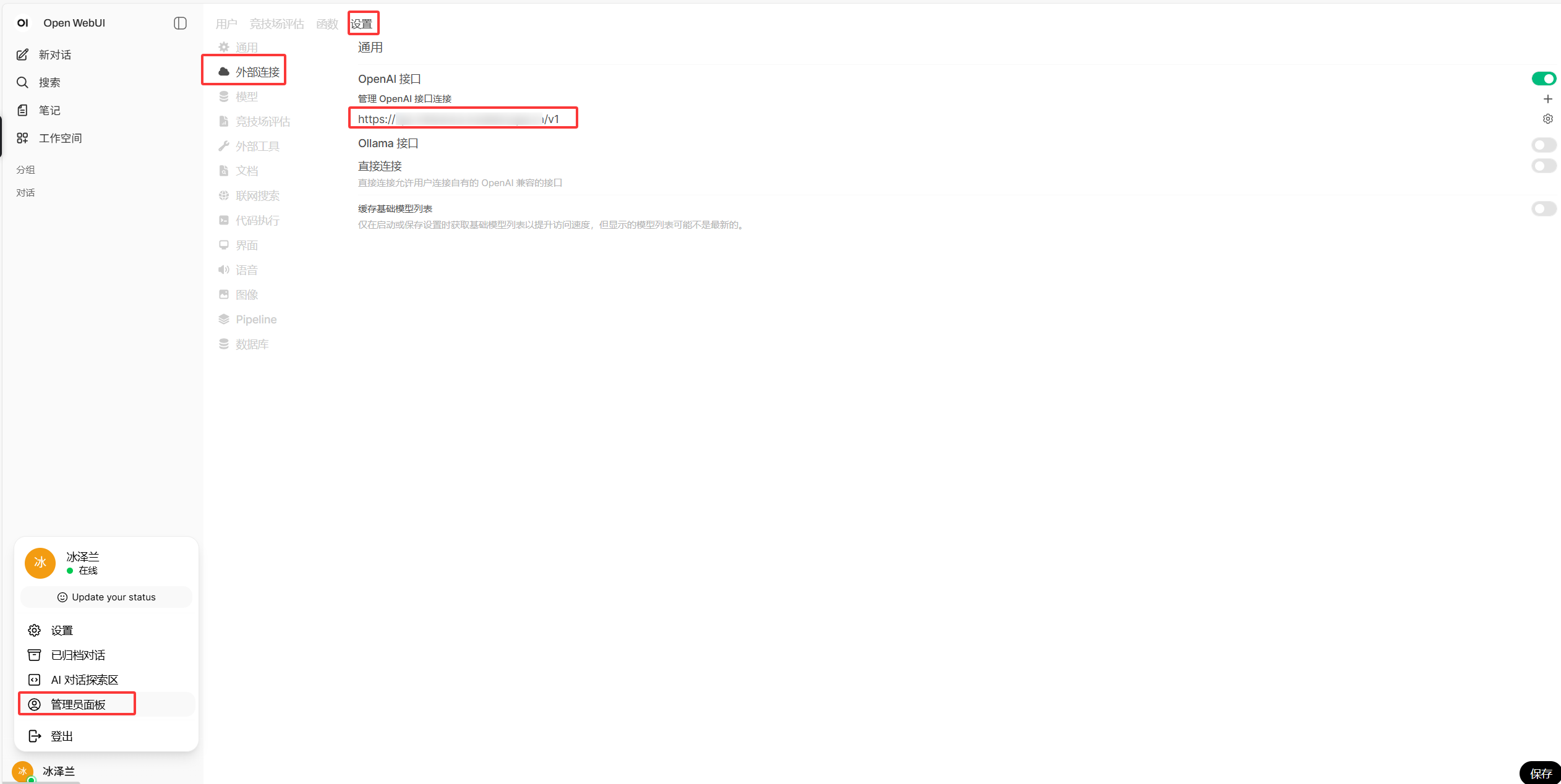
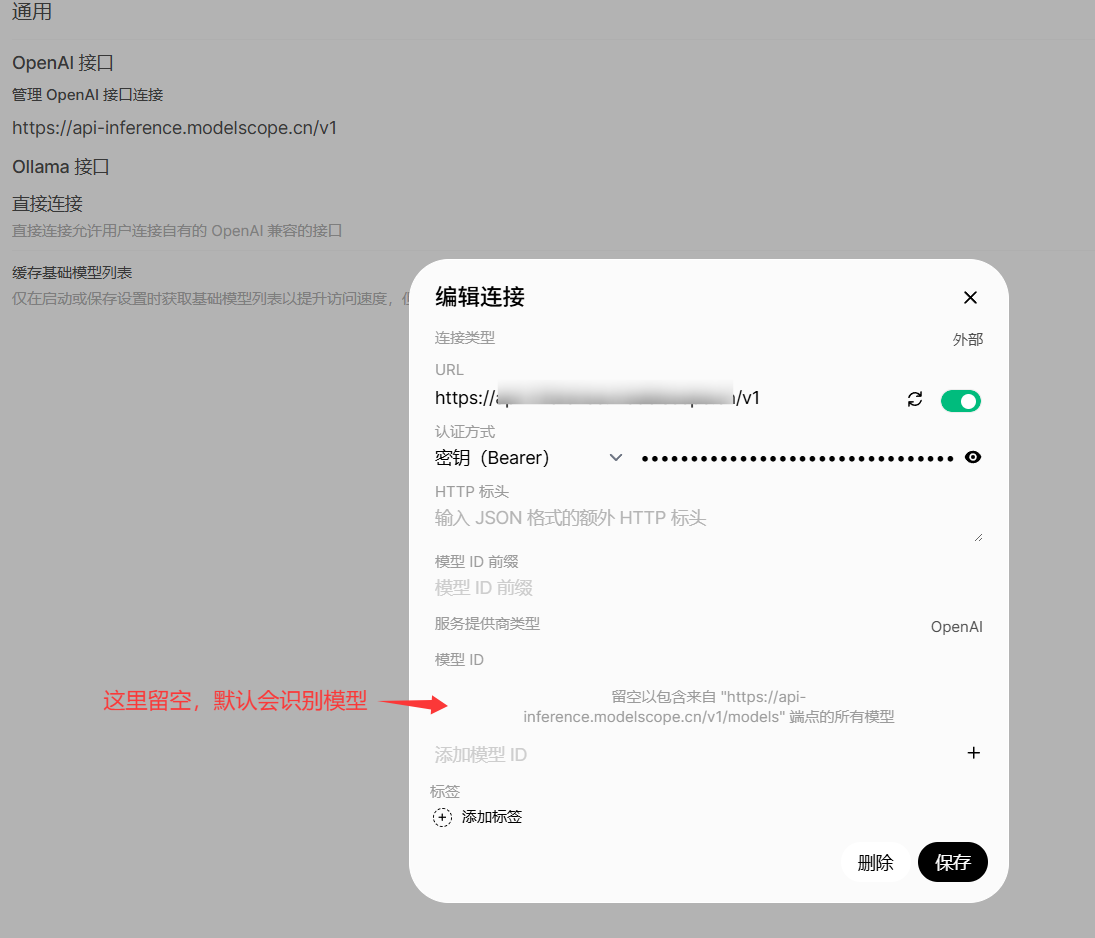
如何配置外部api
做下角点击头像=》设置=》外部链接=》编辑openai接口
使用ragflow知识库
dockercompose部署ragflow
将github上的代码拉下来,直接用dockercompose启动即可
注意
- 如果ollama使用cpu时,选择没有gpu后缀的启动即可
- 如果ollama使用gpu时,需要使用后缀代gpu的ragflow配置文件启动,否则会导致无法解析文档
注册并登录
http://localhost/login账号密码随便设置
账号:admin@qq.com
密码:admin
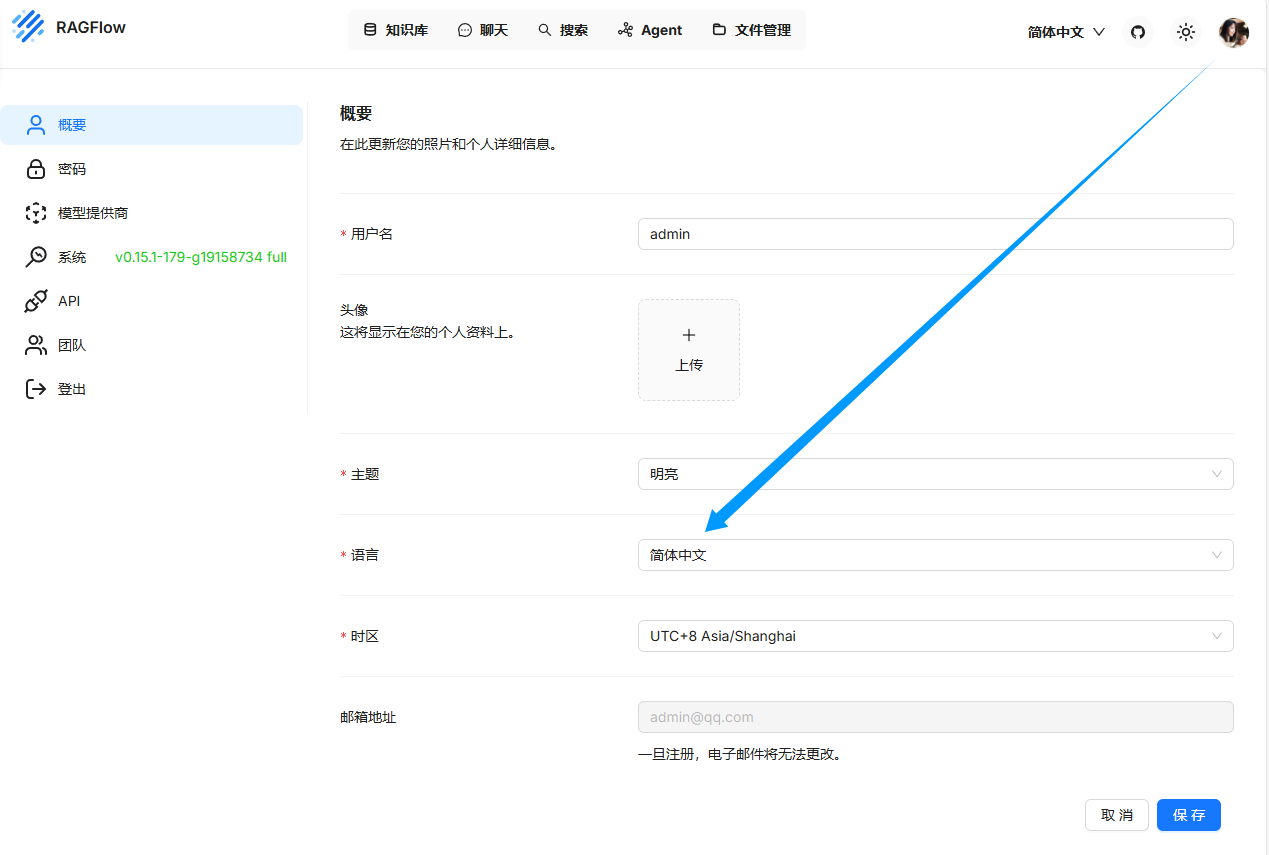
修改界面为中文
接入ollama
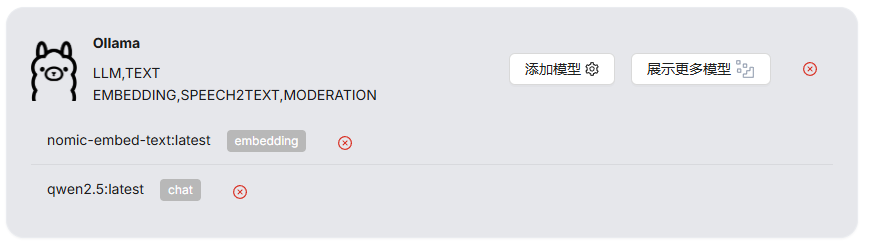
当前我下载了的模型
添加向量模型(用于知识库分片,这个模型需要单独下载)
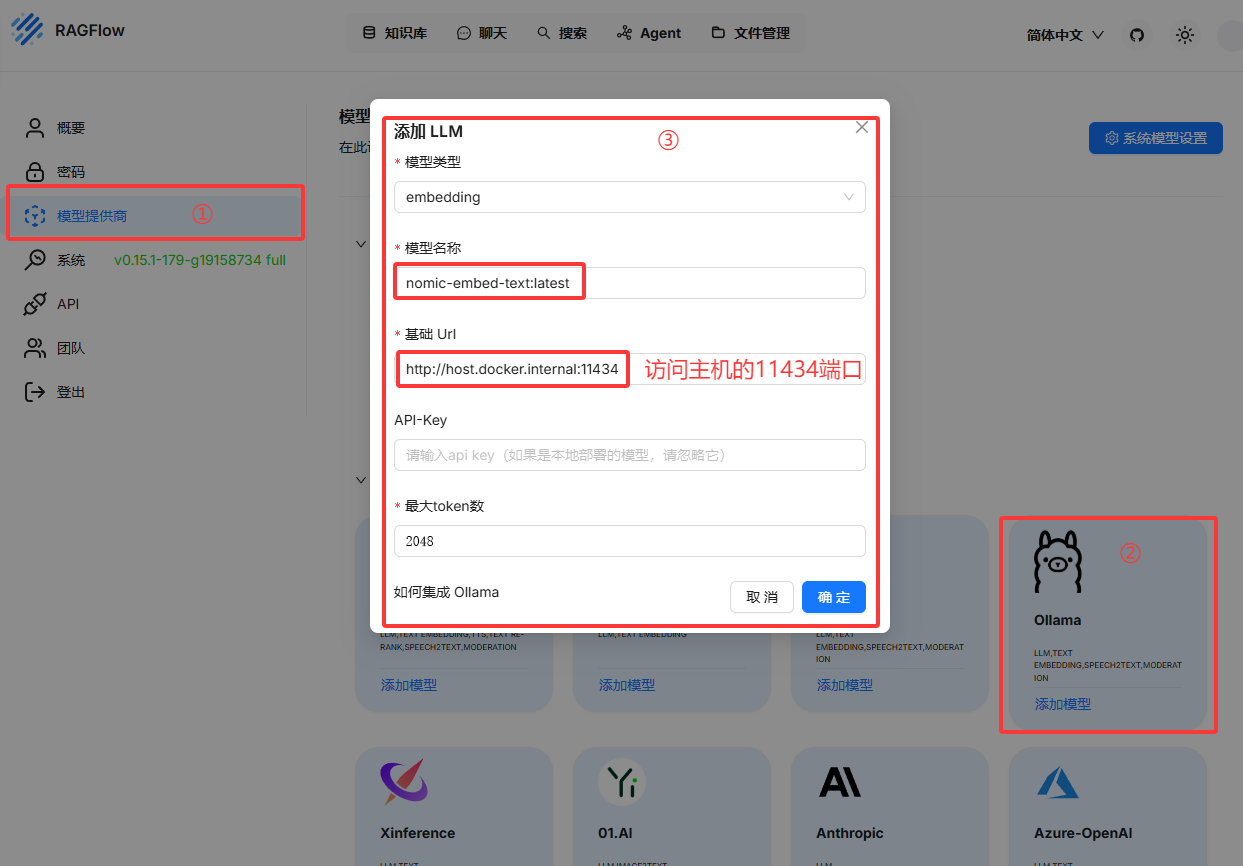
模型名称:nomic-embed-text:latest
基础url:http://host.docker.internal:11434
最大token数(这个在LMStudio中可以看到):2048添加chat模型,此处模型为qwen2.5:7b
- 如果ollama使用gpu的话,由于需要将模型加载到显存中,添加时可能会慢一些
- 如果使用cpu模式的话,添加挺快,就是之后执行知识库检索挺慢
- 如果添加成向量模型,可以点击添加模型重新添加,他会覆盖同名的模型
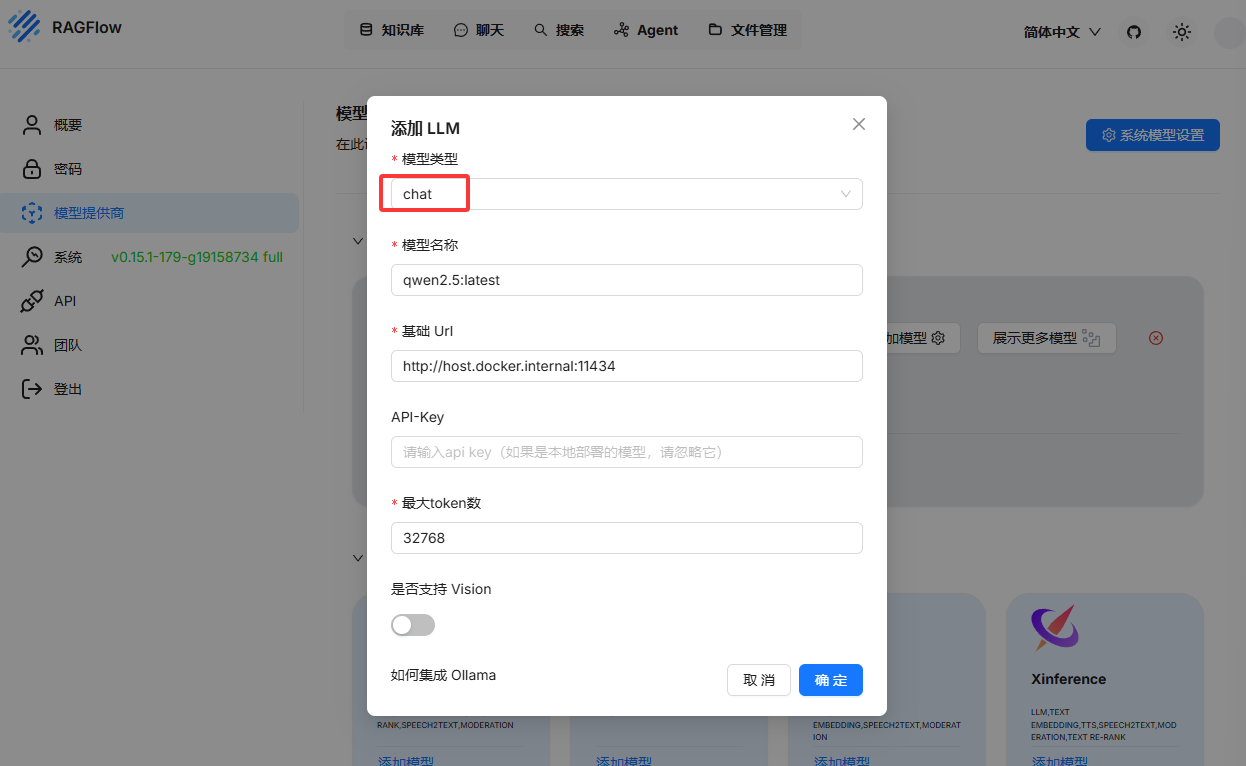
模型名称:qwen2.5:latest
基础url:http://host.docker.internal:11434
最大token数(这个在LMStudio中可以看到):32768加载到显存后即添加完成
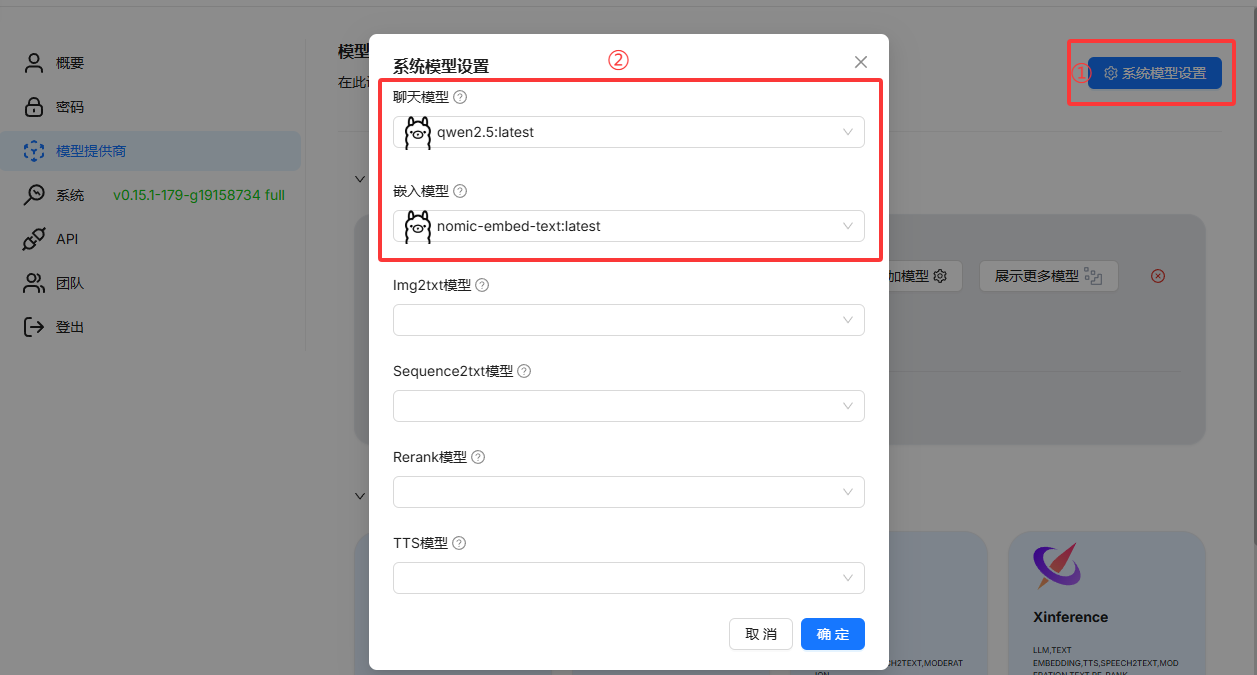
现在就加载了两个模型了,然后需要在系统模型设置中设置对应的模型
接入lmstudio
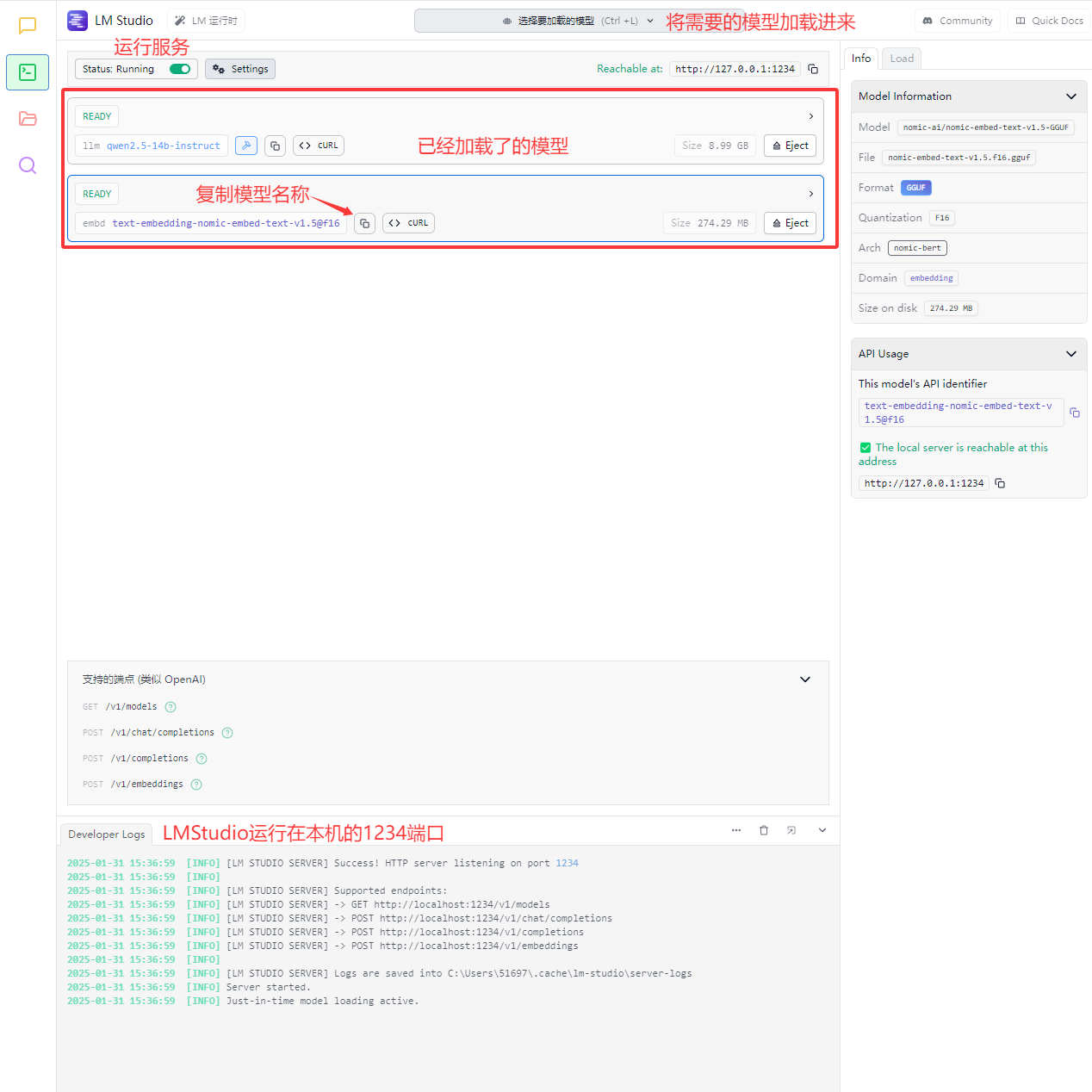
加载模型并启动服务
模型名称也可以手动加载后复制(建议用上图的方法,因为模型会在使用时自动根据ragflow的配置加载)
在ragflow中添加模型
添加向量模型(用于知识库分片,这个模型在LMStudio中自带)
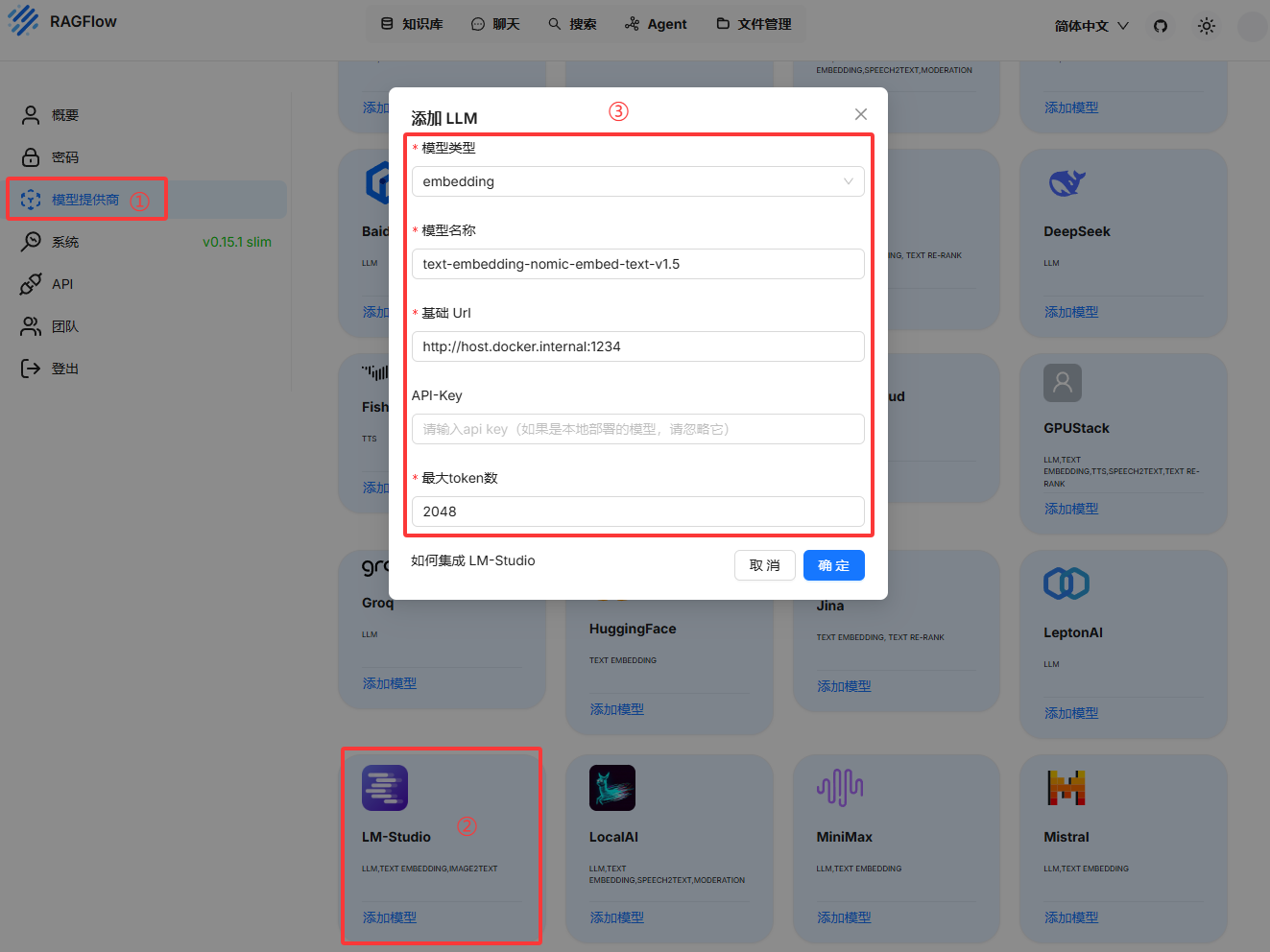
模型名称:text-embedding-nomic-embed-text-v1.5
基础url:http://host.docker.internal:1234
最大token数:2048添加chat模型
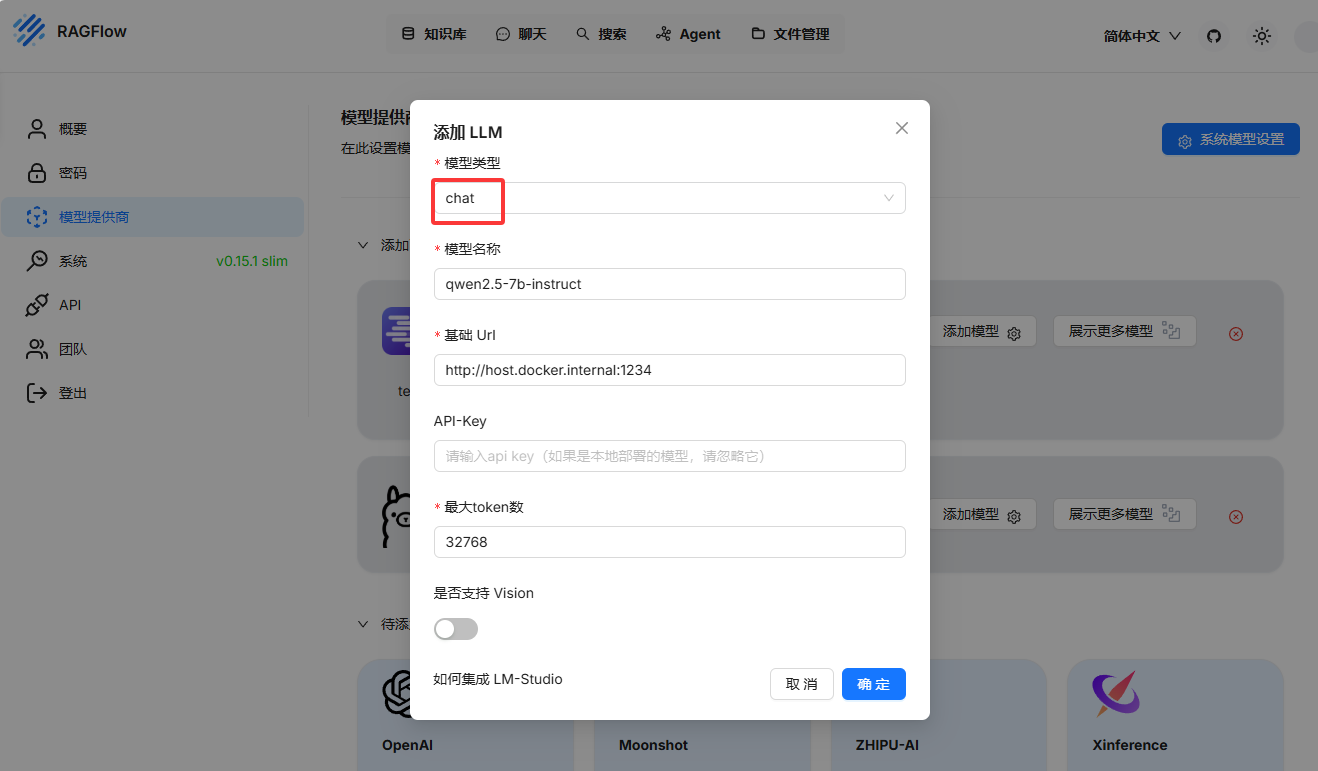
模型名称:qwen2.5-7b-instruct
基础url:http://host.docker.internal:1234
最大token数:32768配置系统模型
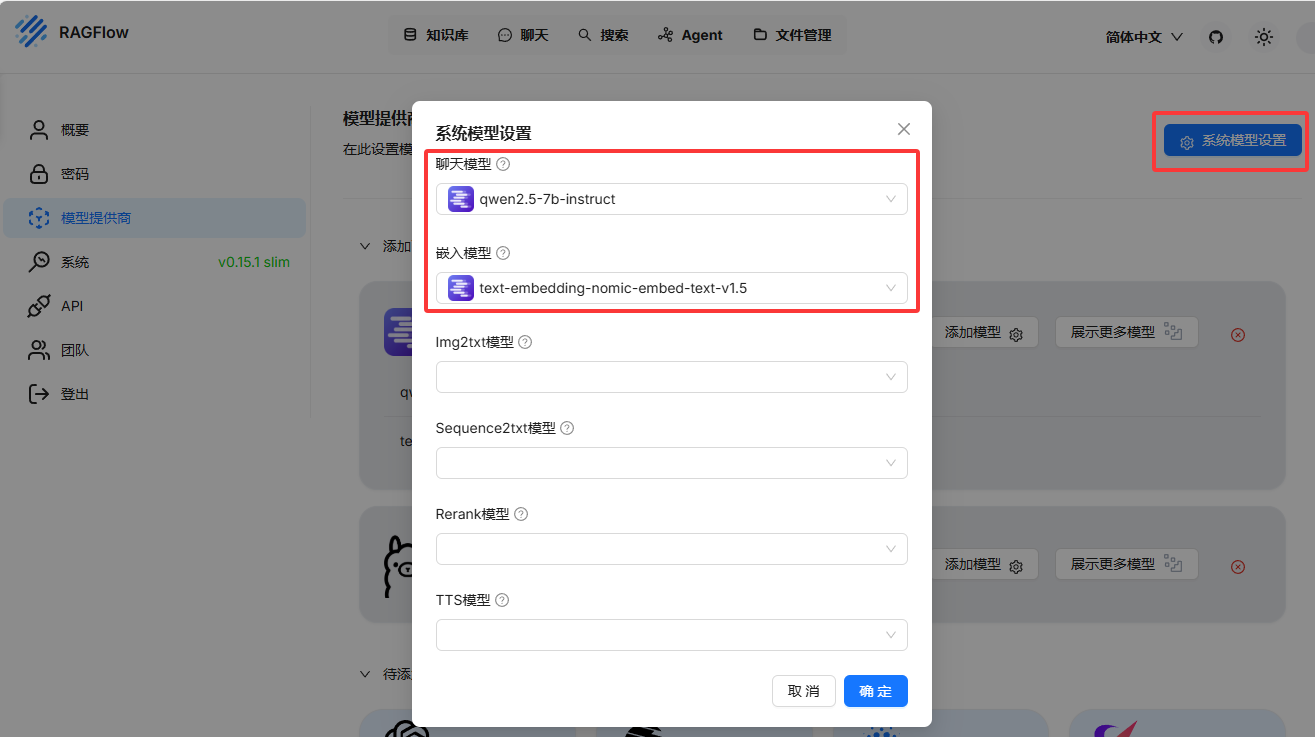
使用测试
新建知识库
新建
新建知识库之后会自动生成配置(支持类型在图中右侧,支持类型会根据
解析方法改变)
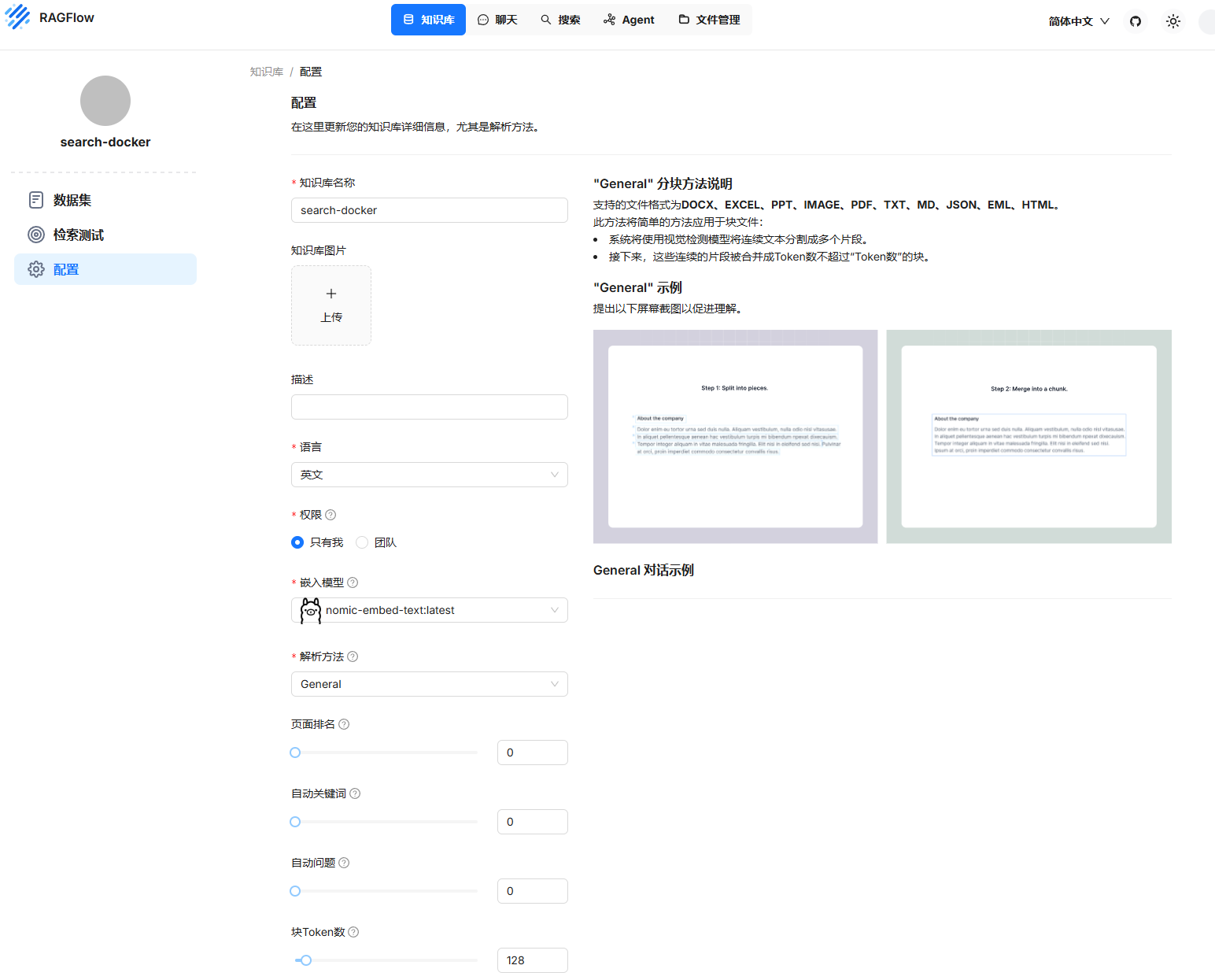
注意
当你配置了ollama的向量模型,如果你想改为LMStudio,你就得重新创建一个知识库,并选择LMStudio的向量模型,否则会报链接失败的错误 
上传知识文档并解析
新建数据集,这里将我的docker笔记转成pdf后上传上去用于测试
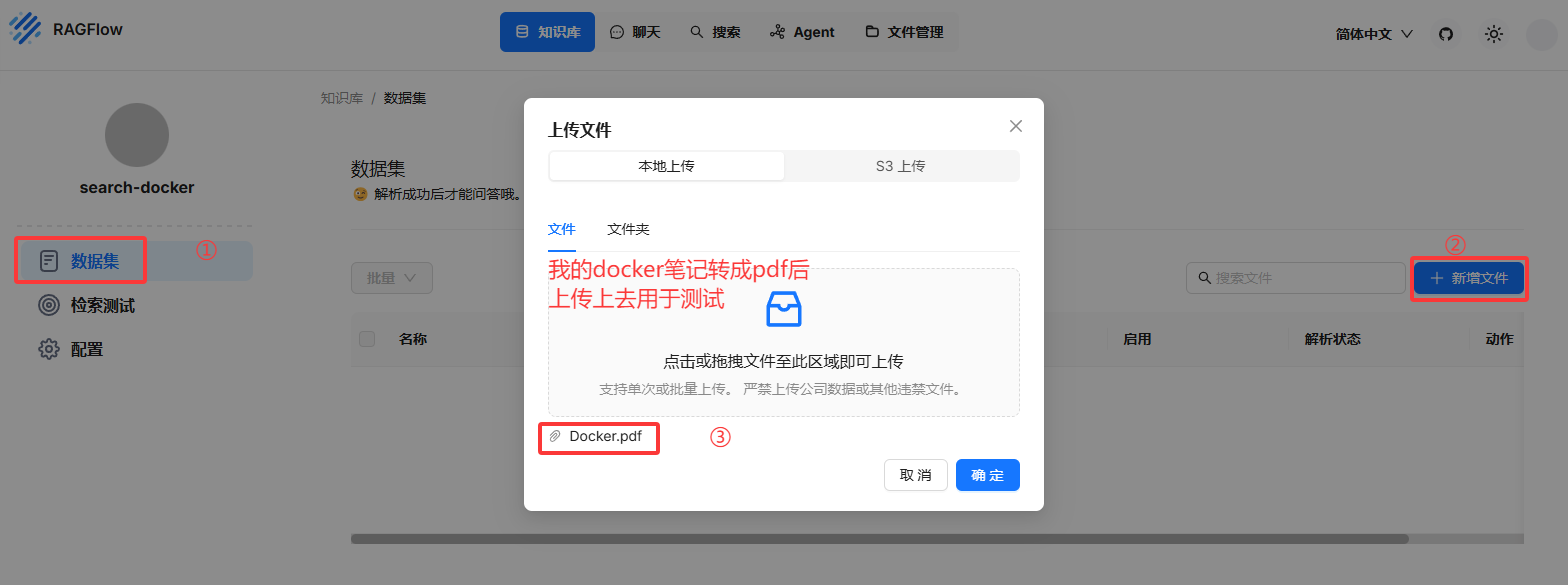
ollama
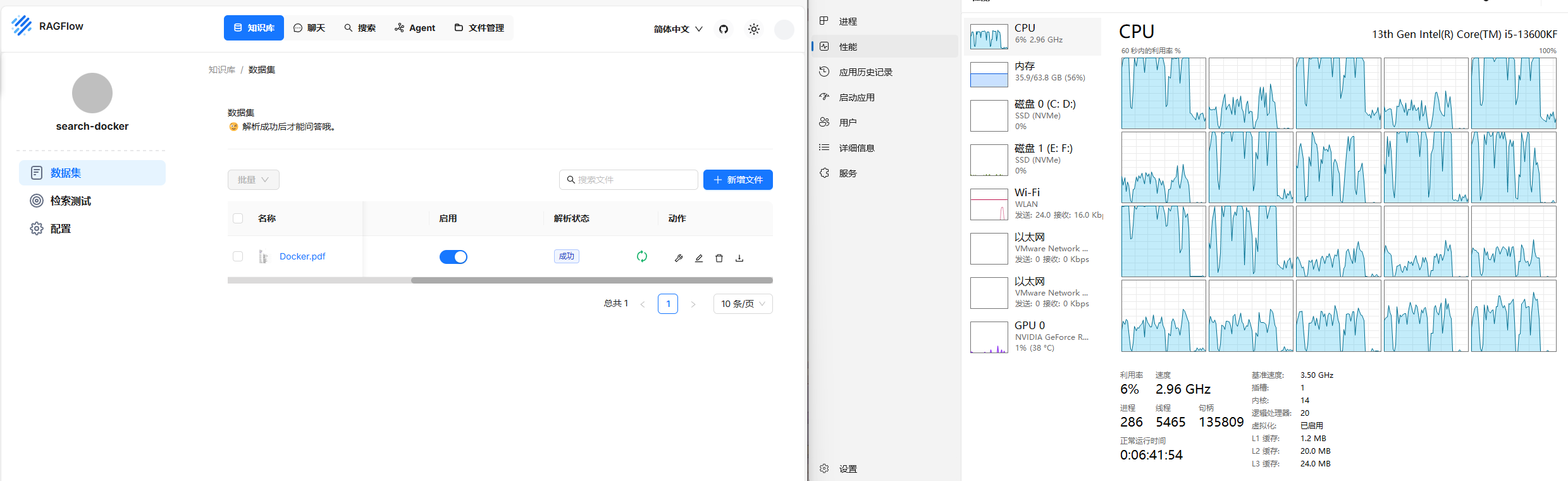
开始解析,解析文档不会用gpu,需要等待cpu解析文档(cpu占用约75%)
在进行解析时是使用cpu资源,不会消耗显卡资源
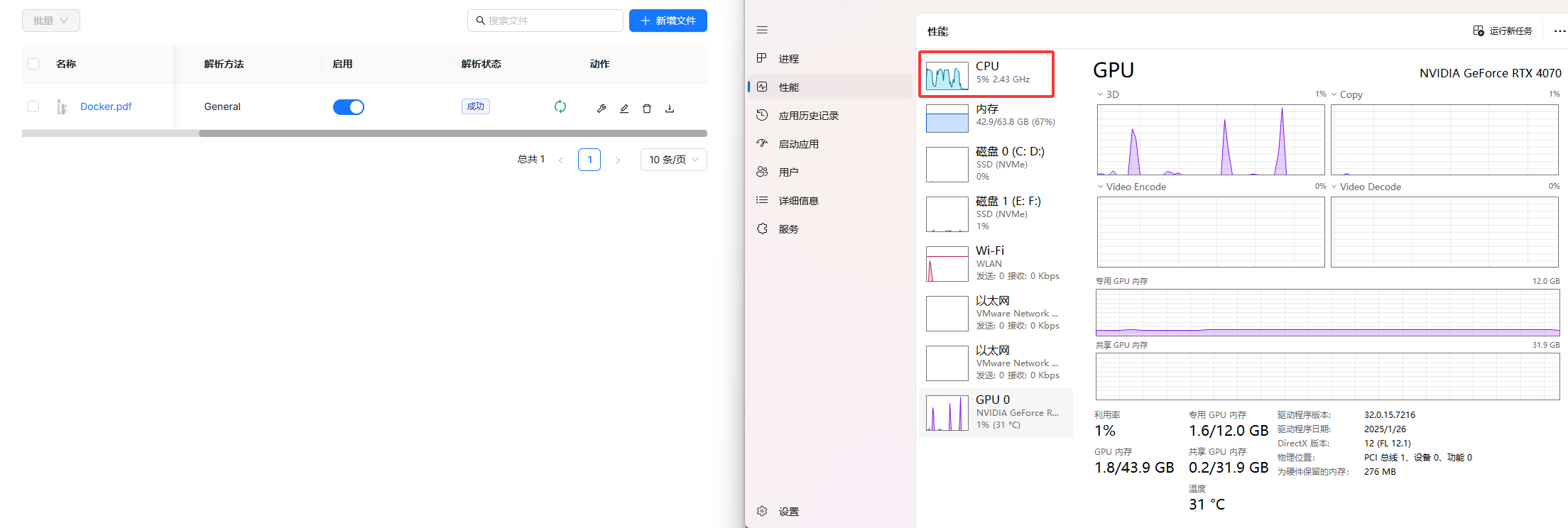
lmstudio
(cpu占用约75%)
测试是否能正常检索
ollama
新建助理
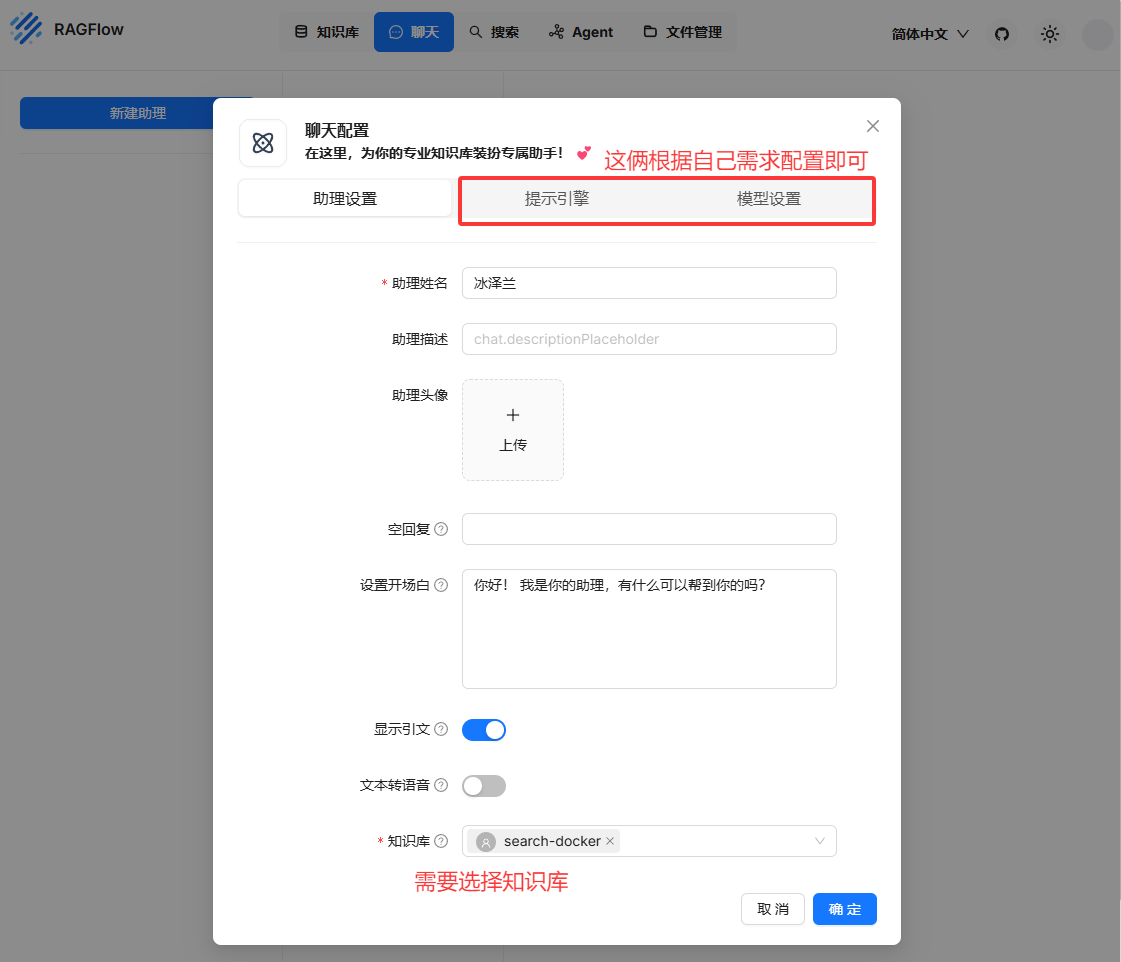
尝试让其搜索如何配置prometheus
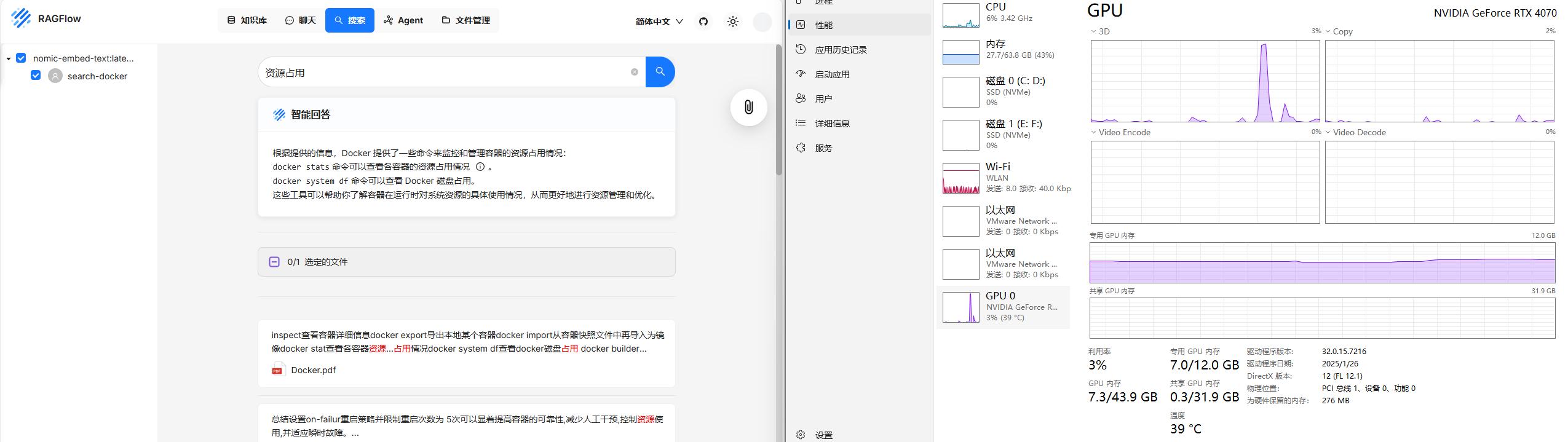
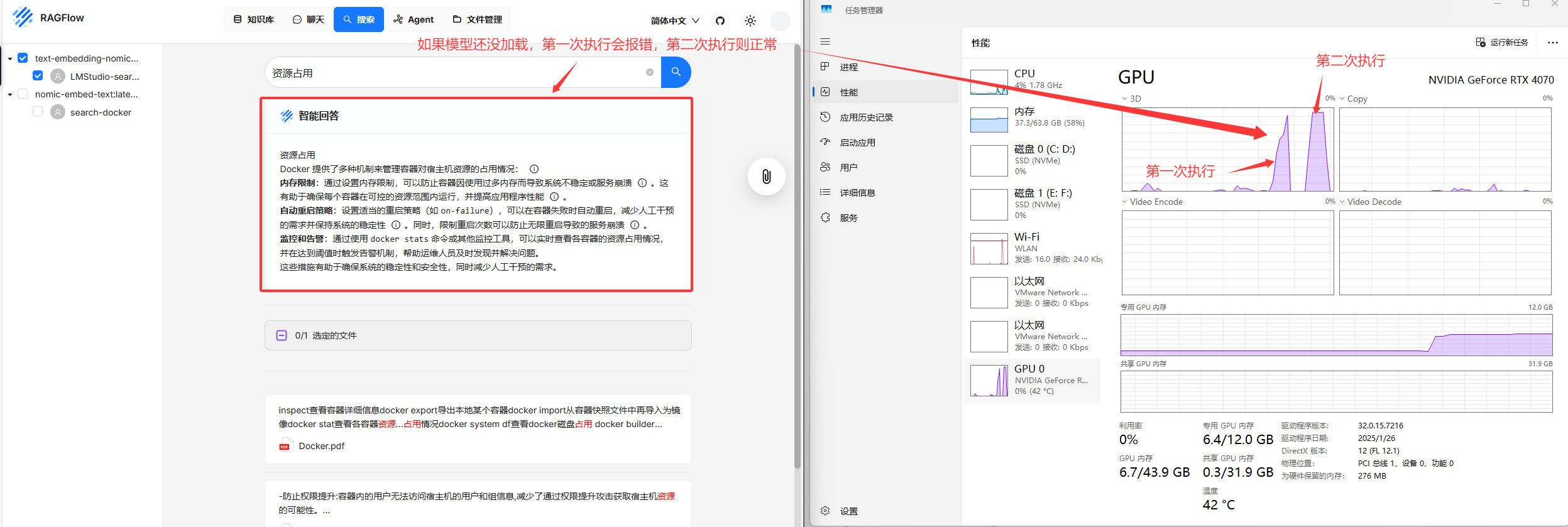
尝试让他给我docker查看资源占用情况的命令
lmstudio
新建助理
尝试让其搜索如何配置prometheus
尝试让他给我docker查看资源占用情况的命令
测试文件检索
ollama
lmstudio
obsidian使用copilot插件
lm studio需要启用cors
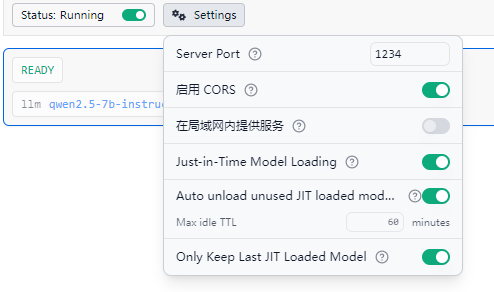
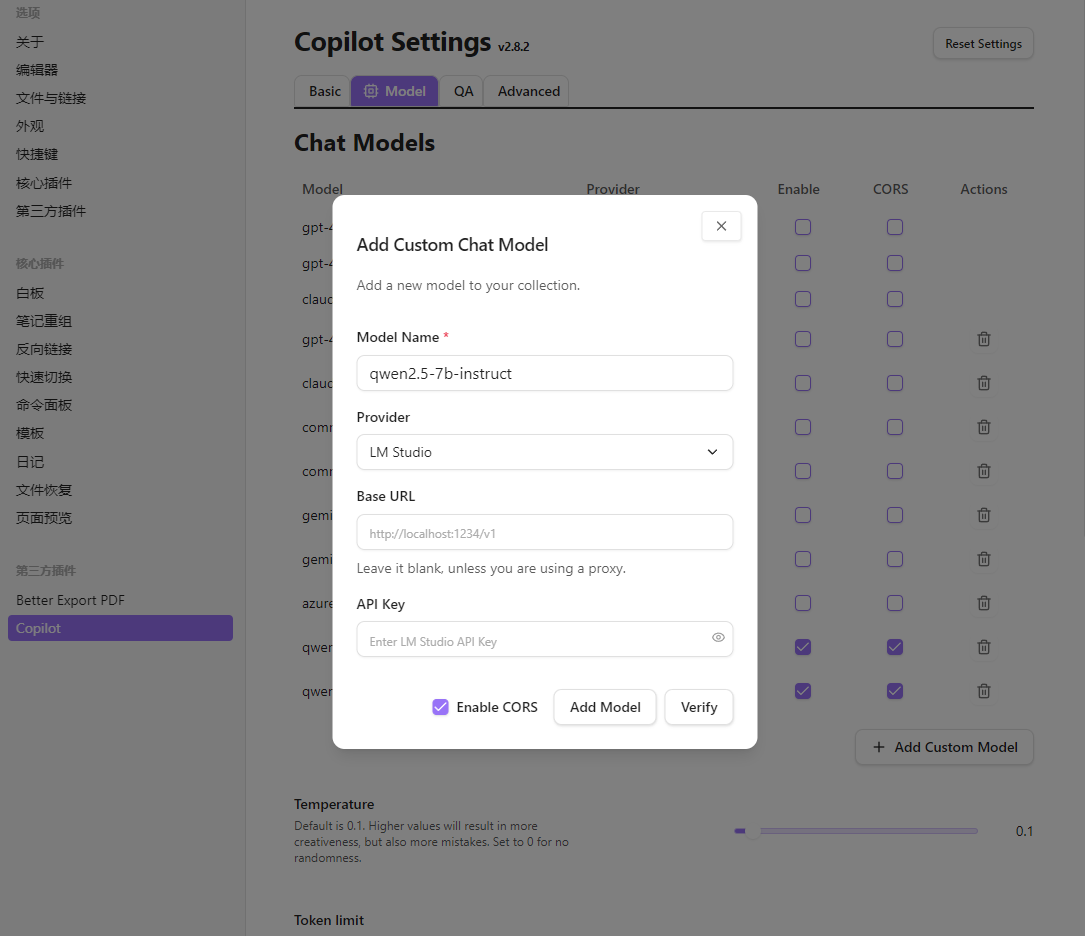
按照下图方式配置之后,点击右下角
校验按钮,测试模型是否能使用
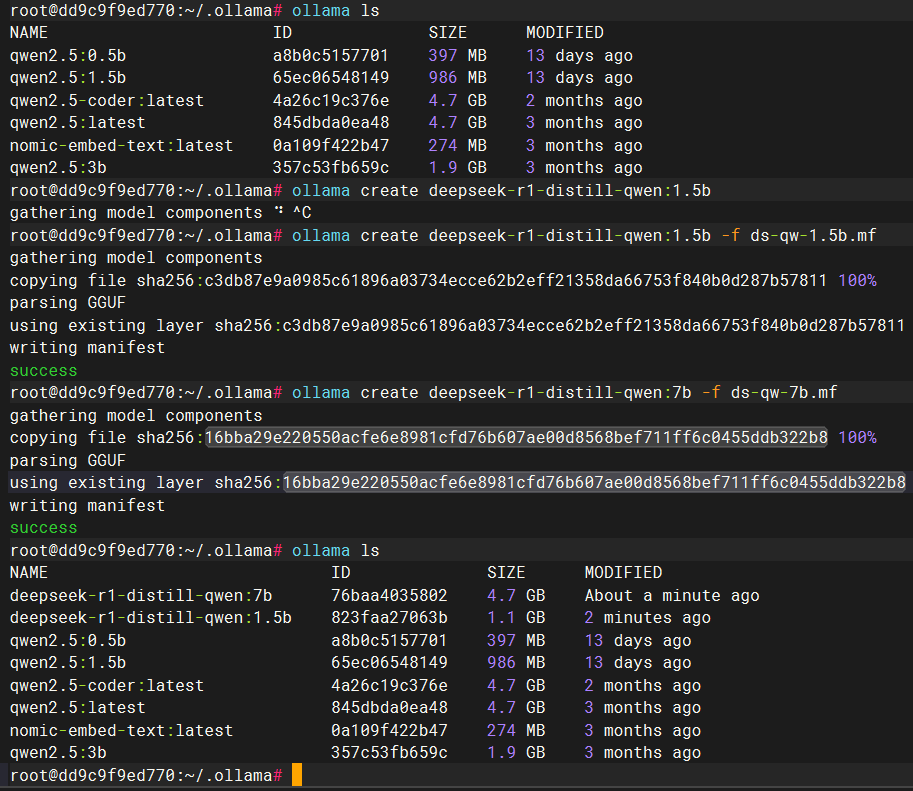
ollama导入gguf模型
创建对应的mf文件
创建
ds-qw-1.5b.mf,from后面需要跟上模型的位置和名称(此处以deepseek的qwen1.5蒸馏模型为例)
FROM ./DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
根据mf文件导入模型
# 进到gguf模型存放目录(我的数据卷映射到这了)
cd /root/.ollama/
# 根据mf文件导入模型
ollama create deepseek-r1-distill-qwen:1.5b -f ds-qw-1.5b.mf