Kubernetes
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
命令速查表
容器、镜像管理
| 命令 | 说明 |
|---|---|
| crictl attach | 连接到正在运行的容器 |
| crictl checkpoint | 检查点保存一个或多个运行中的容器 |
| crictl completion | 输出 shell 自动补全代码 |
| crictl config | 获取、设置和列出 crictl 配置选项 |
| crictl create | 创建新容器 |
| crictl events | 流式输出容器事件 |
| crictl exec | 在运行中的容器中执行命令 |
| crictl imagefsinfo | 返回镜像文件系统信息 |
| crictl images | 列出镜像 |
| crictl info | 显示容器运行时信息 |
| crictl inspect | 显示一个或多个容器的状态 |
| crictl inspecti | 返回一个或多个镜像的状态 |
| crictl inspectp | 显示一个或多个 Pod 的状态 |
| crictl logs | 获取容器日志 |
| crictl metricsp | 列出 Pod 指标(用于替代 cAdvisor 的 /metrics/cadvisor 端点的非结构化键值对) |
| crictl pods | 列出 Pod |
| crictl port-forward | 将本地端口转发到 Pod |
| crictl ps | 列出容器 |
| crictl pull | 从镜像仓库拉取镜像 |
| crictl rm | 删除一个或多个容器 |
| crictl rmi | 删除一个或多个镜像 |
| crictl rmp | 删除一个或多个 Pod |
| crictl run | 在沙箱中运行新容器 |
| crictl runp | 运行新的 Pod |
| crictl runtime-config | 获取容器运行时配置 |
| crictl start | 启动一个或多个已创建的容器 |
| crictl stats | 列出容器资源使用统计信息 |
| crictl statsp | 列出 Pod 统计信息(用于满足 Kubelet 的 /stats/summary 端点) |
| crictl stop | 停止一个或多个运行中的容器 |
| crictl stopp | 停止一个或多个运行中的 Pod |
| crictl update | 更新一个或多个运行中的容器 |
| crictl update-runtime-config | 更新运行时配置 |
| crictl version | 显示运行时版本信息 |
| crictl help | 显示命令列表或特定命令的帮助信息 |
删除所有 Exited 状态的容器
crictl rm $(crictl ps -a | grep Exited | awk '{print $1}')k8s集群管理
| 命令类型 | 命令 | 说明 |
|---|---|---|
| 基础命令(初学者) | kubectl create | 从文件或标准输入创建资源 |
| kubectl expose | 将副本控制器、服务、部署或 Pod 暴露为新的 Kubernetes 服务 | |
| kubectl run | 在集群上运行特定镜像 | |
| kubectl set | 为对象设置指定特性 | |
| 基础命令(中级) | kubectl explain | 获取资源的文档说明 |
| kubectl get | 显示一个或多个资源 | |
| kubectl edit | 编辑服务器上的资源 | |
| kubectl delete | 通过文件名、标准输入、资源名称或标签选择器删除资源 | |
| 部署命令 | kubectl rollout | 管理资源的发布 |
| kubectl scale | 为部署、副本集或副本控制器设置新的规模 | |
| kubectl autoscale | 自动伸缩部署、副本集、有状态集或副本控制器 | |
| 集群管理命令 | kubectl certificate | 修改证书资源 |
| kubectl cluster-info | 显示集群信息 | |
| kubectl top | 显示资源(CPU/内存)使用情况 | |
| kubectl cordon | 标记节点为不可调度 | |
| kubectl uncordon | 标记节点为可调度 | |
| kubectl drain | 清空节点以准备维护 | |
| kubectl taint | 更新一个或多个节点上的污点 | |
| 故障排查和调试命令 | kubectl describe | 显示特定资源或资源组的详细信息 |
| kubectl logs | 打印 Pod 中容器的日志 | |
| kubectl attach | 挂接到一个运行中的容器 | |
| kubectl exec | 在某个容器中执行一个命令 | |
| kubectl port-forward | 将一个或多个本地端口转发到某个 Pod | |
| kubectl proxy | 运行一个指向 Kubernetes API 服务器的代理 | |
| kubectl cp | 在容器间复制文件和目录 | |
| kubectl auth | 检查授权 | |
| kubectl debug | 创建用于故障排查工作负载和节点的调试会话 | |
| kubectl events | 列出事件 | |
| 高级命令 | kubectl diff | 比较实时版本与待应用版本的差异 |
| kubectl apply | 通过文件名或标准输入对资源应用配置 | |
| kubectl patch | 更新资源的字段 | |
| kubectl replace | 通过文件名或标准输入替换资源 | |
| kubectl wait | 实验性:等待一个或多个资源的特定条件 | |
| kubectl kustomize | 从目录或 URL 构建 kustomization 目标 | |
| 设置命令 | kubectl label | 更新某资源上的标签 |
| kubectl annotate | 更新一个资源的注解 | |
| kubectl completion | 为指定的 shell 输出自动补全代码 | |
| 其他命令 | kubectl api-resources | 打印服务器上支持的 API 资源 |
| kubectl api-versions | 以 "组/版本" 的形式打印服务器支持的 API 版本 | |
| kubectl config | 修改 kubeconfig 文件 | |
| kubectl plugin | 提供与插件交互的实用工具 | |
| kubectl version | 显示版本信息 |
检查 API Server 日志
journalctl -xeu kubelet官网
k8s的特性
kubernetes具有以下特性:
- 自动部署和回滚
Kubernetes 会分步骤地将针对应用或其配置的更改上线,同时监视应用程序运行状况以确保你不会同时终止所有实例。如果出现问题,Kubernetes 会为你回滚所作更改。你应该充分利用不断成长的部署方案生态系统。 - 服务发现和负载均衡
你无需修改应用来使用陌生的服务发现机制。Kubernetes 为每个 Pod 提供了自己的 IP 地址并为一组 Pod 提供一个 DNS 名称,并且可以在它们之间实现负载均衡。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 存储编排
自动挂载所选存储系统,包括本地存储、公有云提供商所提供的存储或者诸如 iSCSI 或 NFS 这类网络存储系统。 - Secret 和配置管理 部署和更新 Secret 和应用程序的配置而不必重新构建容器镜像, 且不必将软件堆栈配置中的秘密信息暴露出来。
- 自动装箱
根据资源需求和其他限制自动放置容器,同时避免影响可用性。 将关键性的和尽力而为性质的工作负载进行混合放置,以提高资源利用率并节省更多资源。 - 批量执行 除了服务之外,Kubernetes 还可以管理你的批处理和 CI 工作负载,在期望时替换掉失效的容器。
- IPv4/IPv6 双协议栈 为 Pod 和 Service 分配 IPv4 和 IPv6 地址
- 水平扩缩 使用一个简单的命令、一个 UI 或基于 CPU 使用情况自动对应用程序进行扩缩。
- 为扩展性设计 无需更改上游源码即可扩展你的 Kubernetes 集群。
Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
下载地址(暂时用不到)
安装前需要知道的一些知识
Docker、containerd、CRI-O 和 runc 之间的区别
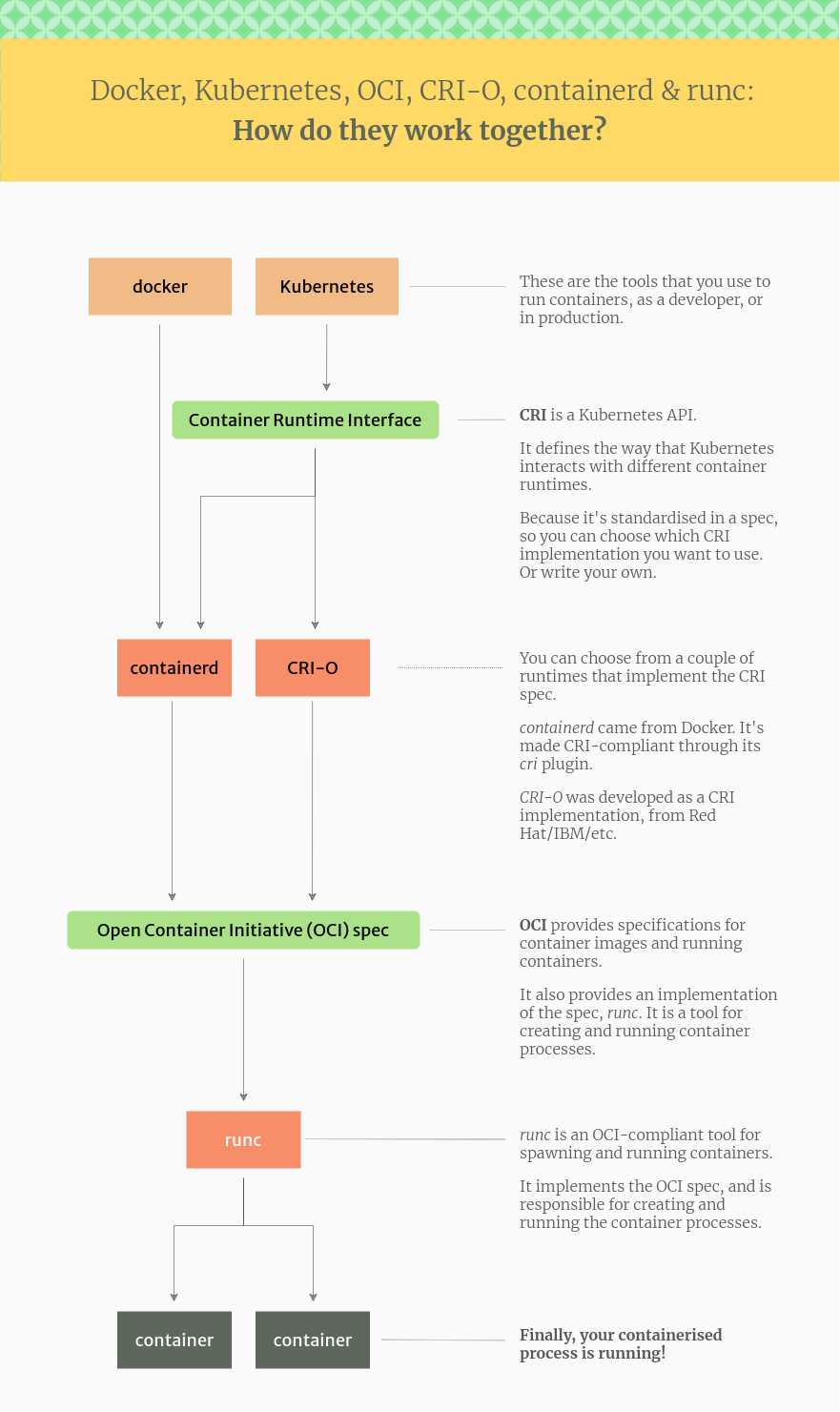
 从第一张图中可以知道,docker、k8s都是用来运行容器的工具; 容器生态系统中的关键角色:
从第一张图中可以知道,docker、k8s都是用来运行容器的工具; 容器生态系统中的关键角色:
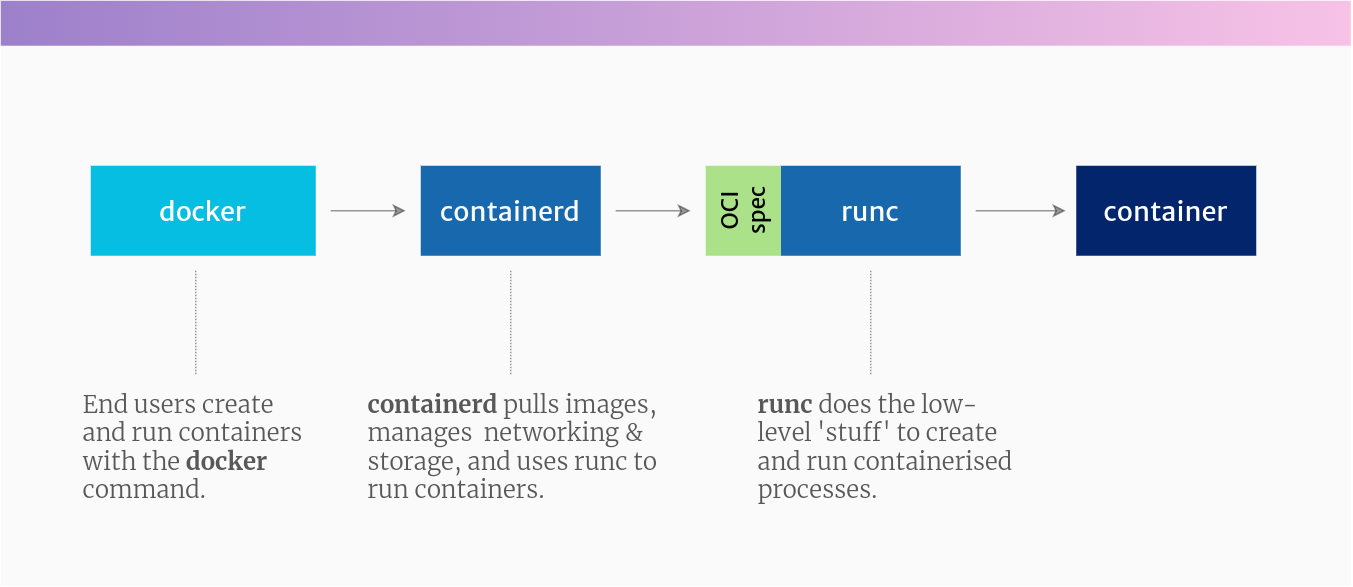
- Docker: 最流行的容器开发工具(Docker Engine),包含命令行工具 (
docker)、Docker 守护进程 (dockerd),以及用于构建和运行容器的底层工具。Docker Desktop 是面向开发者的桌面应用,包含 Docker Engine 和 Kubernetes。 - containerd: 一个高级容器运行时,最初来自 Docker 项目。它负责镜像管理、存储、网络等,然后将创建容器的任务交给低级运行时。Docker Engine 内部使用 containerd。
- CRI-O: 另一个高级容器运行时(Red Hat 开发),与 containerd 功能类似,也是 Kubernetes 的容器运行时选项。
- runc: 一个低级容器运行时,实现了 OCI 标准。它利用 Linux 内核的功能(如命名空间和控制组)来创建和运行容器进程。containerd 和 CRI-O 都会使用 runc(或其他符合 OCI 的低级运行时)来实际运行容器。 重要标准:
- OCI (Open Container Initiative): 容器的开放标准,定义了容器镜像格式、运行时和分发规范。目的是让不同的容器工具可以互操作。
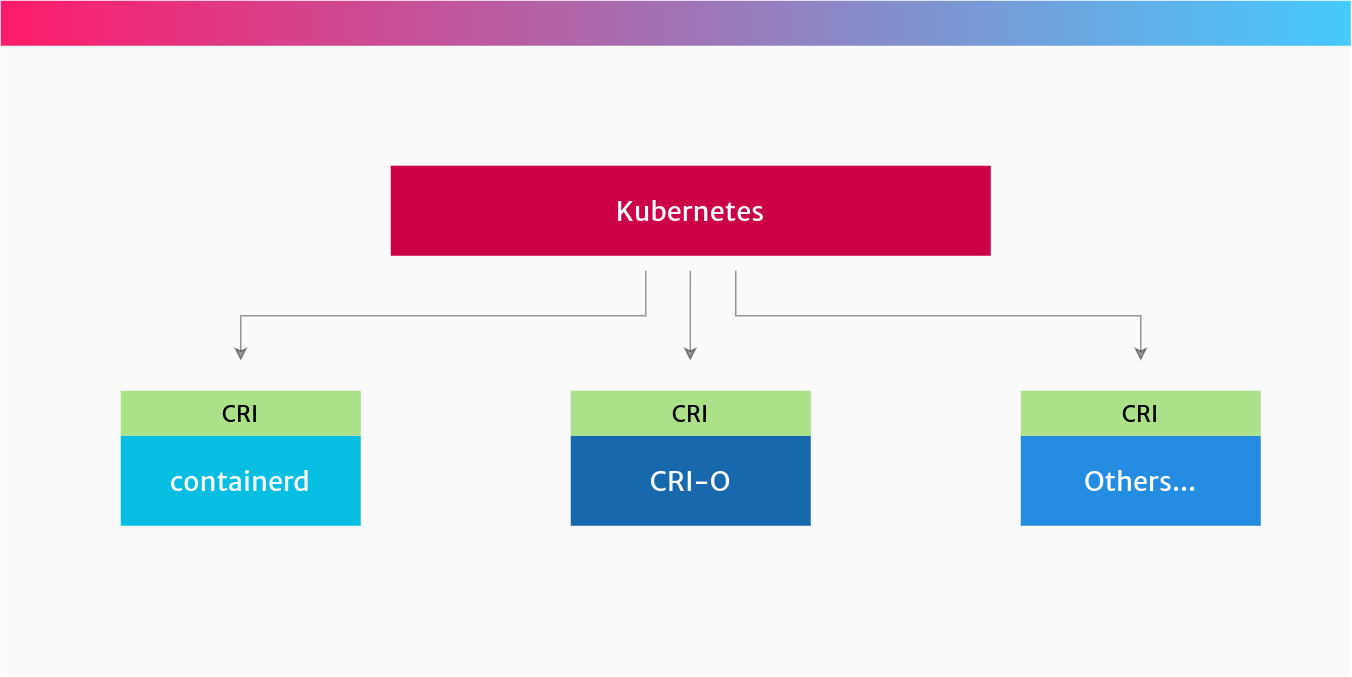
- CRI (Container Runtime Interface): Kubernetes 定义的 API,允许 Kubernetes 使用不同的容器运行时(如 containerd 或 CRI-O)。 Docker、containerd、CRI-O 和 runc 的关系(从上到下):
- 开发者使用 Docker CLI (
docker命令): 这是与容器交互的最上层工具。 - Docker CLI 调用 Docker 守护进程 (
dockerd): 守护进程提供 API 并与容器运行时通信。 - Docker 守护进程使用 containerd: containerd 处理镜像、存储等,并准备好容器运行环境。
- containerd (或 CRI-O) 使用 runc: runc 是实际创建和运行容器进程的低级运行时。 Kubernetes 与容器运行时
- Kubernetes 最初使用 Docker Engine 来运行容器,但后来通过 CRI 接口实现了与容器运行时的解耦。
- Kubernetes 1.24 版本之后,完全移除了对 Docker Engine 的直接支持(移除了 dockershim 组件)。Kubernetes 对容器运行时的支持变化
- 现在,Kubernetes 使用实现了 CRI 的容器运行时,如 containerd 或 CRI-O。
- 这并不意味着 Kubernetes 不能运行 Docker 格式的镜像。containerd 和 CRI-O 都可以运行 Docker 格式和 OCI 格式的镜像。
Kubernetes 对容器运行时的支持变化
Before K8s 1.24:
Kubernetes → dockershim(内置) → Docker → containerd → 容器
After K8s 1.24:
Kubernetes → containerd → 容器容器相关
crictl
这是一个命令行工具,用于与CRI(Container Runtime Interface,容器运行时接口)兼容的容器运行时进行交互,和docker的用法一样
网络相关
CNI(Container Network Interface)
容器网络接口,定义了容器网络配置的标准,常见实现:Flannel、Calico
Flannel
一个 CNI 插件,为容器提供网络功能,负责分配 IP 和路由
iptables
Linux 的网络防火墙工具,管理网络包的转发规则,Kubernetes 用它来实现服务访问
Kubernetes 组件
kubeadm
Kubernetes 的安装工具,用于初始化集群,管理集群节点
kubelet
运行在每个节点上的代理,负责管理容器的生命周期,确保容器在 Pod 中运行
kubectl
Kubernetes 的命令行工具,用于管理 Kubernetes 集群,部署和管理应用
对比docker,如何管理镜像
crictl会在安装 kubelet、kubeadm、kubectl 时,cri-tools 作为依赖被自动安装
# 容器操作
docker ps → crictl ps
docker logs → crictl logs
docker exec → crictl exec
docker rm → crictl rm
# 镜像操作
docker images → crictl images
docker pull → crictl pull
docker rmi → crictl rmi
# 系统信息
docker info → crictl info
docker version → crictl version关于镜像源的更换
配置k8s的镜像源
这里的源用于拉取 Kubernetes 系统组件的镜像,只影响 Kubernetes 系统组件
配置contained的镜像源
containerd 的镜像源用于拉取普通应用容器的镜像,与docker配置镜像加速是一个意思
安装k8s(根据官方文档,需要代理)
注意
1.当前时间为2025年2月11日,当前支持的k8s最新版为1.32,因此该方法以k8s的1.32版本为例 2.我的系统里装有docker,因此我没有再次安装containerd
基础环境准备
需要如下准备:
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令。
- 每台机器 2 GB 或更多的 RAM(如果少于这个数字将会影响你应用的运行内存)。
- 控制平面机器需要 CPU 2 核心或更多。
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)。
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 开启机器上的某些端口。请参见这里了解更多详细信息。
- 交换分区的配置。kubelet 的默认行为是在节点上检测到交换内存时无法启动。 更多细节参阅交换内存管理。
- 如果 kubelet 未被正确配置使用交换分区,则你必须禁用交换分区。 例如,
sudo swapoff -a将暂时禁用交换分区。要使此更改在重启后保持不变,请确保在如/etc/fstab、systemd.swap等配置文件中禁用交换分区,具体取决于你的系统如何配置。
基本配置
设置主机名称
# 各个机器设置自己的域名
hostnamectl set-hostname xxxx关闭selinux
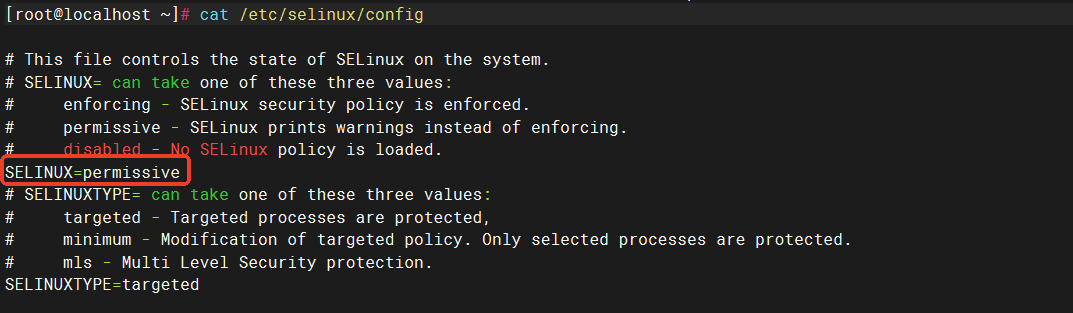
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config禁用selinux其实就是将
/etc/selinux/config中的SELINUX的值改为permissive
关闭交换分区
# 关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab禁用交换分区其实就是将
/etc/fstab中的交换分区那行注释了
配置网络所需参数
注意
/etc/modules-load.d 是 Linux 系统中用于管理内核模块自动加载的目录。 overlay用于容器的覆盖网络,允许创建容器间的虚拟网络,Docker 和 Kubernetes 的网络都需要这个模块; br_netfilter用于桥接网络过滤,允许 iptables 对桥接 IPv4/IPv6 流量进行处理,确保容器网络可以正确路由
将网络配置加入linux自动加载目录
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
# 立即加载这些模块,不需要重启
modprobe overlay
modprobe br_netfilter
# 允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system如果报错就看这
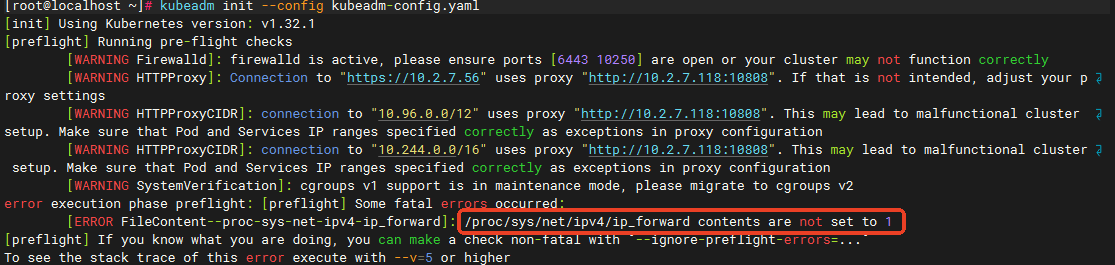
这里的
net.ipv4.ip_forward可能会被/etc/sysctl.conf覆盖,如果后续执行k8s初始化时报如下错误,则需要去修改主配置文件/etc/sysctl.conf中的net.ipv4.ip_forward
检查所有相关配置文件
# 检查所有 sysctl 配置文件
grep -r "ip_forward" /etc/sysctl.d/
grep -r "ip_forward" /etc/sysctl.conf修改 ip_forward 设置
sed -i 's/net.ipv4.ip_forward=0/net.ipv4.ip_forward=1/g' /etc/sysctl.conf验证修改
grep "ip_forward" /etc/sysctl.conf重新加载配置
# 重新加载所有 sysctl 配置
sysctl --system
# 验证设置
cat /proc/sys/net/ipv4/ip_forward # 应该输出 1配置代理(如果使用其他的镜像源,并且github能连接上,可以不用做代理相关的步骤)
基本模块安装的代理
容器运行时的代理(安装了containerd或docker之后再配置)
10.2.7.118:10809请改为你自己的代理地址;注意这里的noproxy加上了自己的机器配置10.2.7.56,master,不加可能会导致初始化集群失败
# 创建containerd的代理配置
mkdir -p /etc/systemd/system/containerd.service.d/
cat <<EOF | tee /etc/systemd/system/containerd.service.d/proxy.conf
[Service]
Environment="HTTP_PROXY=http://10.2.7.118:10809"
Environment="HTTPS_PROXY=http://10.2.7.118:10809"
Environment="NO_PROXY=localhost,127.0.0.1,10.96.0.0/12,10.244.0.0/16,10.2.7.56,master,.cluster.local,.svc"
EOF
# 重启服务
systemctl daemon-reload
systemctl restart containerdssh配置临时代理(注意:no_proxy中需要加上初始化时需要的网络及其自己的网络否则可能会导致安装网络插件时报错;或者在代理端加上对应的hosts也行)
export http_proxy="http://10.2.7.118:10809"
export https_proxy="http://10.2.7.118:10809"
export all_proxy="socks5://10.2.7.118:10809"
export no_proxy="localhost,127.0.0.1,10.96.0.0/12,10.244.0.0/16,10.2.7.56,master"
检查是否配置成功
systemctl show containerd --property Environment删除代理
# 删除 containerd 代理配置文件
rm -f /etc/systemd/system/containerd.service.d/proxy.conf
# 如果目录为空,也可以删除目录
rmdir /etc/systemd/system/containerd.service.d重新加载服务
# 重新加载 systemd 配置
systemctl daemon-reload
# 重启 containerd
systemctl restart containerd验证代理已经关闭
# 检查环境变量
env | grep -i proxy
# 检查 containerd 配置
systemctl show containerd | grep -i proxy
# 检查 kubelet 配置(如果已安装)
systemctl show kubelet | grep -i proxykubelet 的代理(根据自己情况加代理)
(注意:no_proxy中需要加上初始化时需要的网络及其自己的网络否则可能会导致安装网络插件时报错;或者在代理端加上对应的hosts也行)
# 创建或修改 kubelet 代理配置
mkdir -p /etc/systemd/system/kubelet.service.d/
cat <<EOF | tee /etc/systemd/system/kubelet.service.d/proxy.conf
[Service]
Environment="HTTP_PROXY=http://10.2.7.118:10809"
Environment="HTTPS_PROXY=http://10.2.7.118:10809"
Environment="NO_PROXY=localhost,127.0.0.1,10.96.0.0/12,10.244.0.0/16,10.2.7.56,master,.cluster.local,.svc"
EOF
# 重启 kubelet
systemctl daemon-reload
systemctl restart kubelet检查是否配置成功
systemctl show kubelet --property Environment删除代理
# 删除 kubelet 代理配置文件
rm -f /etc/systemd/system/kubelet.service.d/proxy.conf
# 如果目录为空,也可以删除目录
rmdir /etc/systemd/system/kubelet.service.d重新加载服务
# 重新加载 systemd 配置
systemctl daemon-reload
# 重启 kubelet
systemctl restart kubelet验证代理已经关闭
# 检查环境变量
env | grep -i proxy
# 检查 containerd 配置
systemctl show containerd | grep -i proxy
# 检查 kubelet 配置(如果已安装)
systemctl show kubelet | grep -i proxy安装容器运行时containerd
有docker,则配置containerd
# 备份默认的配置
cp /etc/containerd/config.toml /etc/containerd/config.toml.bak
# 生成默认配置文件
containerd config default | tee /etc/containerd/config.toml
# 修改配置使用systemd cgroup驱动
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
# 重启containerd
systemctl restart containerd没有docker,则安装containerd
# 安装 containerd
dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
dnf install -y containerd.io
# 创建默认配置文件
mkdir -p /etc/containerd
containerd config default | tee /etc/containerd/config.toml
# 修改配置使用 systemd cgroup 驱动
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
# 启动 containerd
systemctl enable containerd
systemctl start containerd注意
SystemdCgroup = false 改为 SystemdCgroup = true 的含义:
- 将 containerd 的 cgroup 驱动从默认的 cgroupfs 切换到 systemd- systemd 是现代 Linux 系统的默认初始化系统和服务管理器
- 使用 systemd cgroup 驱动可以避免出现两个不同的 cgroup 管理器的问题
配置镜像加速(使用代理可以不配置这一步)
Containerd 的镜像源用于拉取普通应用容器的镜像,可以参考docker的加速地址进行配置
修改containerd的配置
cd /etc/containerd/修改下述内容(endpoint这里可以配置多个镜像加速地址)
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.1ms.run"]重启container
systemctl restart containerd安装 kubelet、kubeadm 和 kubectl
基于 Debian 的发行版
更新 apt 包索引并安装使用 Kubernetes apt 仓库所需要的包
sudo apt-get update
# apt-transport-https 可能是一个虚拟包(dummy package);如果是的话,你可以跳过安装这个包
sudo apt-get install -y apt-transport-https ca-certificates curl gpg下载用于 Kubernetes 软件包仓库的公共签名密钥。所有仓库都使用相同的签名密钥,因此你可以忽略URL中的版本
# 如果 `/etc/apt/keyrings` 目录不存在,则应在 curl 命令之前创建它,请阅读下面的注释。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.32/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg说明
在低于 Debian 12 和 Ubuntu 22.04 的发行版本中,/etc/apt/keyrings 默认不存在。 应在 curl 命令之前创建它。
添加 Kubernetes apt 仓库
请注意,此仓库仅包含适用于 Kubernetes 1.32 的软件包; 对于其他 Kubernetes 次要版本,则需要更改 URL 中的 Kubernetes 次要版本以匹配你所需的次要版本 (你还应该检查正在阅读的安装文档是否为你计划安装的 Kubernetes 版本的文档)
# 此操作会覆盖 /etc/apt/sources.list.d/kubernetes.list 中现存的所有配置。
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.32/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl基于 Red Hat 的发行版
将 SELinux 设置为 permissive 模式
以下指令适用于 Kubernetes 1.32。
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config注意
- 通过运行命令
setenforce 0和sed ...将 SELinux 设置为 permissive 模式相当于将其禁用。 这是允许容器访问主机文件系统所必需的,例如,某些容器网络插件需要这一能力。 你必须这么做,直到 kubelet 改进其对 SELinux 的支持。 - 如果你知道如何配置 SELinux 则可以将其保持启用状态,但可能需要设定部分 kubeadm 不支持的配置。
添加 Kubernetes 的 yum 仓库
在仓库定义中的
exclude参数确保了与 Kubernetes 相关的软件包在运行yum update时不会升级,因为升级 Kubernetes 需要遵循特定的过程。请注意,此仓库仅包含适用于 Kubernetes 1.32 的软件包; 对于其他 Kubernetes 次要版本,则需要更改 URL 中的 Kubernetes 次要版本以匹配你所需的次要版本 (你还应该检查正在阅读的安装文档是否为你计划安装的 Kubernetes 版本的文档)。
# 此操作会覆盖 /etc/yum.repos.d/kubernetes.repo 中现存的所有配置
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF安装 kubelet、kubeadm 和 kubectl,并启用 kubelet 以确保它在启动时自动启动
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
sudo systemctl enable --now kubelet安装CNI插件
# 安装CNI插件
mkdir -p /opt/cni/bin
cd /tmp
wget https://github.com/containernetworking/plugins/releases/download/v1.6.2/cni-plugins-linux-amd64-v1.6.2.tgz
tar xf cni-plugins-linux-amd64-v1.6.2.tgz -C /opt/cni/bin/
chmod -R 755 /opt/cni/bin验证crictl是否正常工作
crictl info初始化Kubernetes集群
注意
建议初始化时不要开代理;如果配置了代理,但是初始化失败,建议检查kubelet的代理是否正确,是否在no_proxy中加上了自己机器的端口和域名
配置host
将
10.2.7.56的域名配置为master,将10.2.7.113的域名配置为worker,
cat >> /etc/hosts << EOF
10.2.7.56 master
10.2.7.113 worker
EOF单机模式
通过配置文件初始化
如果需要换源(没有代理的时候),请在
集群配置部分加上imageRepository: registry.aliyuncs.com/google_containers # 配置阿里云镜像仓库这里的源用于拉取 Kubernetes 系统组件的镜像
# 创建kubeadm配置文件
cat <<EOF | tee kubeadm-config.yaml
# API 版本和初始化配置
apiVersion: kubeadm.k8s.io/v1beta4 # kubeadm API 版本
kind: InitConfiguration # 配置类型为初始化配置
localAPIEndpoint: # API 服务器端点配置
advertiseAddress: 10.2.7.56 # 控制平面对外公布的IP地址
bindPort: 6443 # API 服务器监听端口
nodeRegistration: # 节点注册相关配置
criSocket: "unix:///run/containerd/containerd.sock" # 容器运行时接口地址
---
# 集群配置部分
apiVersion: kubeadm.k8s.io/v1beta4 # kubeadm API 版本
kind: ClusterConfiguration # 配置类型为集群配置
networking: # 网络配置部分
podSubnet: 10.244.0.0/16 # Pod 网络的 IP 地址范围(Flannel 使用)
serviceSubnet: 10.96.0.0/12 # Service 网络的 IP 地址范围
EOF拉取必要镜像
kubeadm config images pull --config kubeadm-config.yaml初始化集群
kubeadm init --config kubeadm-config.yaml通过命令行初始化
kubeadm init \
--apiserver-advertise-address=10.2.7.56 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--cri-socket=unix:///run/containerd/containerd.sock- --apiserver-advertise-address: 指定 API 服务器的广播地址
- --pod-network-cidr: 指定 Pod 网络的 CIDR
- --service-cidr: 指定 Service 网络的 CIDR
- --cri-socket: 指定容器运行时接口
- --v=5: 显示详细的日志信息,方便排查问题(可选项)
- --image-repository:配置镜像仓库(可选项)
- --kubernetes-version:v1.32.2(可选项)
执行结果
[init] Using Kubernetes version: v1.32.2
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[WARNING SystemVerification]: cgroups v1 support is in maintenance mode, please migrate to cgroups v2
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
W0218 16:44:17.779936 245824 checks.go:846] detected that the sandbox image "registry.k8s.io/pause:3.8" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry.k8s.io/pause:3.10" as the CRI sandbox image.
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.96.0.1 10.2.7.56]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [10.2.7.56 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [10.2.7.56 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 500.745946ms
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 7.501102086s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: 2k3oc2.3lx2jrjs5rdey88w
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.2.7.56:6443 --token 2k3oc2.3lx2jrjs5rdey88w \
--discovery-token-ca-cert-hash sha256:66e914cecab290acd452d820499ba5fcdd01ef2414c8c239a55f26964842fcb8删除污点
kubectl taint nodes master node-role.kubernetes.io/control-plane:NoSchedule-为什么要删除污点:在上方的初始化日志中,有一段为master节点添加了不允许调度的污点,这会导致单机模式无法运行容器,因此需要删除该污点
# 新增污点日志
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]修复警告
执行结果中有警告提到 sandbox 镜像版本不一致,需要将其版本升到3.10
W0211 16:16:38.834906 311707 checks.go:846] detected that the sandbox image "registry.k8s.io/pause:3.8" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry.k8s.io/pause:3.10" as the CRI sandbox image.升级sandbox版本需要修改containerd的配置文件并重置集群,之后重新初始化集群
# 修改版本号为3.10
sed -i 's|registry.k8s.io/pause:3.8|registry.k8s.io/pause:3.10|g' /etc/containerd/config.toml重新初始化集群
kubeadm init --config kubeadm-config.yaml如果还遇到 etcd 相关错误,使用下面的方式清理
# 完全清理 etcd 数据
rm -rf /var/lib/etcd/*
# 确保 etcd 目录权限正确
mkdir -p /var/lib/etcd
chmod 700 /var/lib/etcd集群模式
通过配置文件初始化
如果需要换源(没有代理的时候),请在
集群配置部分加上imageRepository: registry.aliyuncs.com/google_containers # 配置阿里云镜像仓库这里的源用于拉取 Kubernetes 系统组件的镜像
cat > kubeadm-config.yaml <<EOF
# 集群配置部分
apiVersion: kubeadm.k8s.io/v1beta4 # kubeadm API 版本
kind: ClusterConfiguration # 配置类型为集群配置
kubernetesVersion: v1.32.2 # Kubernetes 版本
controlPlaneEndpoint: "master:6443" # 控制平面端点(高可用集群必需)
networking: # 网络配置
podSubnet: "10.244.0.0/16" # Pod 网络 CIDR(使用 Flannel)
serviceSubnet: "10.96.0.0/12" # Service 网络的 IP 地址范围
# 初始化配置部分
---
apiVersion: kubeadm.k8s.io/v1beta4 # kubeadm API 版本
kind: InitConfiguration # 配置类型为初始化配置
nodeRegistration: # 节点注册配置
criSocket: "unix:///run/containerd/containerd.sock" # 容器运行时套接字
# kubelet 配置部分
---
apiVersion: kubelet.config.k8s.io/v1beta1 # kubelet API 版本
kind: KubeletConfiguration # 配置类型为 kubelet 配置
cgroupDriver: "systemd" # cgroup 驱动程序(需要与容器运行时一致)
EOF拉取必要镜像
kubeadm config images pull --config kubeadm-config.yaml初始化集群
kubeadm init --config kubeadm-config.yaml --upload-certs通过命令行初始化
如果需要换源(没有代理的时候),请加上
--image-repository registry.aliyuncs.com/google_containers \这里的源用于拉取 Kubernetes 系统组件的镜像
kubeadm init \
--apiserver-advertise-address=10.2.7.56 \
--control-plane-endpoint="master" \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--cri-socket=unix:///run/containerd/containerd.sock \
--upload-certs这里也可以写成加上端口的形式
--control-plane-endpoint="master:6443"
kubeadm init \
--apiserver-advertise-address=10.2.7.56 \
--control-plane-endpoint="master:6443" \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--cri-socket=unix:///run/containerd/containerd.sock \
--upload-certs执行结果
[init] Using Kubernetes version: v1.32.2
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[WARNING SystemVerification]: cgroups v1 support is in maintenance mode, please migrate to cgroups v2
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.96.0.1 10.2.7.56]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [10.2.7.56 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [10.2.7.56 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.000754422s
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 14.001533117s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
766545d10d54914f8087d3cd37490b0eadb7600bee645bfb835f3d18c717e31f
[mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: n12ab1.opcyq6c43gw38u7j
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join master:6443 --token n12ab1.opcyq6c43gw38u7j \
--discovery-token-ca-cert-hash sha256:d699cbfeca1849c338b34b05693f5990ad0af1b5695f428492deefca1f6ad98f \
--control-plane --certificate-key 766545d10d54914f8087d3cd37490b0eadb7600bee645bfb835f3d18c717e31f
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join master:6443 --token n12ab1.opcyq6c43gw38u7j \
--discovery-token-ca-cert-hash sha256:d699cbfeca1849c338b34b05693f5990ad0af1b5695f428492deefca1f6ad98f重置节点
# 在 master 节点删除所有 kubernetes 资源
kubectl delete node --all
# 在所有节点执行以下命令
kubeadm reset -f
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
ipvsadm -C
rm -rf ~/.kube
rm -rf /etc/kubernetes/
rm -rf /var/lib/kubelet/
rm -rf /var/lib/etcd/
rm -rf /etc/cni/
rm -rf /var/lib/cni/
systemctl restart containerd
systemctl restart kubelet初始化之后再更换k8s镜像源的方法
这里的源用于拉取 Kubernetes 系统组件的镜像,只影响 Kubernetes 系统组件
切换为阿里镜像源
这个修改是安全的,不会影响当前运行的组件;新的镜像源设置只会影响后续的操作(如升级、新增节点等);原有运行的 Pod 和组件不会受到影响; 建议保存备份文件 kubeadm-config-backup.yaml 以便需要时还原
备份当前配置文件
# 备份当前的 kubeadm 配置
kubectl -n kube-system get cm kubeadm-config -o yaml > kubeadm-config-backup.yaml修改为阿里云镜像源
# 编辑 kubeadm-config configmap
kubectl -n kube-system edit cm kubeadm-config在 data.ClusterConfiguration 中添加或修改
imageRepository: registry.aliyuncs.com/google_containers还原配置
# 方法1:使用备份文件还原
kubectl apply -f kubeadm-config-backup.yaml
# 方法2:直接编辑配置
kubectl -n kube-system edit cm kubeadm-config
# 将 imageRepository 改回原值:registry.k8s.io验证配置
# 查看当前配置
kubectl -n kube-system get cm kubeadm-config -o yaml加入集群
检查现有 token
kubeadm token list加入master节点
需要额外的 certificate-key,新生成的证书和 token 都有效期限制
一条命令搞定
# 对于控制平面节点,使用:
echo "$(kubeadm token create --print-join-command) --control-plane --certificate-key $(kubeadm init phase upload-certs --upload-certs 2>/dev/null | tail -1)"命令步骤拆分
# 1. 重新上传证书并获取新的 certificate-key
kubeadm init phase upload-certs --upload-certs
# 会输出新的 certificate-key
# 2. 生成新的 join 命令
kubeadm token create --print-join-command# 将 join 命令加上 --control-plane 和 --certificate-key
kubeadm join master:6443 --token <new-token> \
--discovery-token-ca-cert-hash sha256:<hash> \
--control-plane --certificate-key <new-certificate-key>加入worker节点
只需要 token 和 hash
# 生成新的 join 命令(适用于 worker 节点)
kubeadm token create --print-join-command
配置kubectl(根据用户类型选择对应的配置方式)
root用户
export KUBECONFIG=/etc/kubernetes/admin.conf第一次配置时,这样是配置成功
如果需要取消KUBECONFIG,请用这句

unset KUBECONFIG检测是否设置成功
echo $KUBECONFIG普通用户
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config安装网络插件
Flannel
注意
- Flannel 默认使用
10.244.0.0/16网段 - 确保 kubeadm init 时使用了匹配的
pod-network-cidr --pod-network-cidr=10.244.0.0/16- 适用场景:小型集群、测试环境
- 特点:配置简单,功能基础
安装
直接安装
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml先下载,再安装
wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml --validate=false检查状态
# 查看所有 pods
kubectl get pods --all-namespaces
# 查看节点状态
kubectl get nodes
# 检查 Flannel pods 状态
kubectl get pods -n kube-flannel -w如果有错误,查看具体日志
kubectl logs -n kube-flannel -l app=flannelCalico
注意
- Calico 默认使用
192.168.0.0/16网段 - 确保 kubeadm init 时使用了匹配的
pod-network-cidr --pod-network-cidr=192.168.0.0/16- 适用场景:生产环境、需要网络策略的场景
- 特点:功能丰富,支持网络策略
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml如果需要修改默认网段(比如改为 10.244.0.0/16)
sed -i 's/192.168.0.0\/16/10.244.0.0\/16/g' calico.yaml
kubectl apply -f calico.yaml配置防火墙
主节点
# 控制面板必需端口
firewall-cmd --permanent --add-port=6443/tcp # Kubernetes API server
firewall-cmd --permanent --add-port=2379-2380/tcp # etcd server client API
firewall-cmd --permanent --add-port=10250/tcp # Kubelet API
firewall-cmd --permanent --add-port=10259/tcp # kube-scheduler
firewall-cmd --permanent --add-port=10257/tcp # kube-controller-manager
# Flannel 需要的端口
firewall-cmd --permanent --add-port=8472/udp # Flannel VXLAN
# 应用端口范围(如果需要)
firewall-cmd --permanent --add-port=30000-32767/tcp # NodePort Services
# 重新加载防火墙配置
firewall-cmd --reload
# 验证端口配置
firewall-cmd --list-ports工作节点
# 工作节点必需端口
firewall-cmd --permanent --add-port=10250/tcp # Kubelet API
firewall-cmd --permanent --add-port=10256/tcp # kube-proxy
# Flannel 需要的端口
firewall-cmd --permanent --add-port=8472/udp # Flannel VXLAN
# 应用端口范围(如果需要)
firewall-cmd --permanent --add-port=30000-32767/tcp # NodePort Services
# 重新加载防火墙配置
firewall-cmd --reload
# 验证端口配置
firewall-cmd --list-ports单机节点
即主节点和工作节点就是同一台机器
# 1. 控制面板端口
firewall-cmd --permanent --add-port=6443/tcp # Kubernetes API server
firewall-cmd --permanent --add-port=2379-2380/tcp # etcd server client API
firewall-cmd --permanent --add-port=10250/tcp # Kubelet API
firewall-cmd --permanent --add-port=10259/tcp # kube-scheduler
firewall-cmd --permanent --add-port=10257/tcp # kube-controller-manager
# 2. 工作节点端口
firewall-cmd --permanent --add-port=10256/tcp # kube-proxy
# 3. Flannel 网络插件端口
firewall-cmd --permanent --add-port=8472/udp # Flannel VXLAN
# 4. NodePort 服务端口范围(如果需要)
firewall-cmd --permanent --add-port=30000-32767/tcp
# 5. 重新加载防火墙配置
firewall-cmd --reload
# 6. 验证端口配置
firewall-cmd --list-ports检查服务连接性
# 在工作节点上测试到主节点的连接
curl -k https://10.2.7.56:6443
# 检查节点状态
kubectl get nodes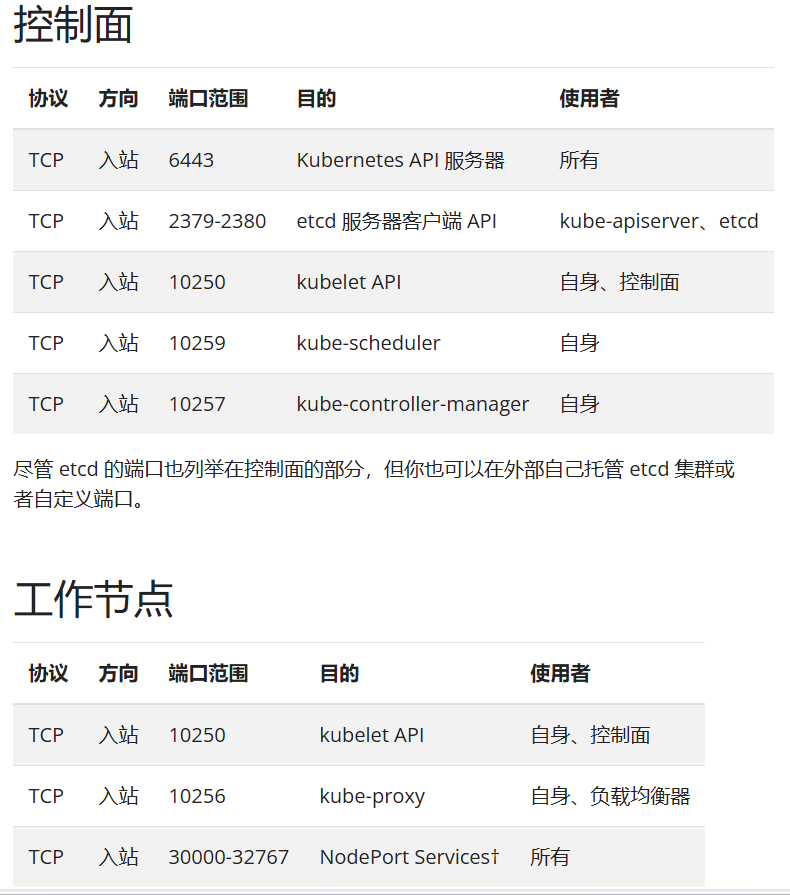
验证集群
# 查看节点状态
kubectl get nodes
# 查看系统Pod状态
kubectl get pods --all-namespaces
# 部署测试应用
kubectl create deployment nginx --image=nginx
# 容器内部端口为80,外部端口为30080,外部通过30080端口访问该nginx容器
kubectl expose deployment nginx --port=80 --node-port=30080 --type=NodePort
kubectl get svc nginx # 如果没有加上--node-port,需要这样获取访问端口卸载k8s(保留 Docker)
清理所有 K8s 资源
# 删除所有命名空间中的资源
kubectl delete all --all --all-namespaces重置 kubeadm
强制重置(不提示确认)(执行这个就行)
kubeadm reset -fkubeadm reset的作用
停止并删除所有 Kubernetes 容器
删除 /etc/kubernetes/ 目录中的配置
删除 /var/lib/kubelet/ 中的数据
删除 /var/lib/etcd/ 中的数据
删除网络相关配置:
删除 CNI 配置和接口
重置网络接口
清理 IPVS 规则
删除所有 Kubernetes 相关的证书和密钥:
API Server 证书
kubelet 证书
CA 证书
Service Account 密钥重置并清理 cni 配置
kubeadm reset --cri-socket unix:///run/containerd/containerd.sock停止并禁用服务
systemctl stop kubelet
systemctl disable kubelet删除 K8s 组件
dnf remove -y kubeadm kubectl kubelet kubernetes-cni kube*清理配置文件和目录
rm -rf /etc/kubernetes/ # Kubernetes 主配置目录,包含证书、配置文件等
rm -rf $HOME/.kube # kubectl 配置文件,包含集群访问凭证
rm -rf /var/lib/kubelet/ # kubelet 工作目录,包含 Pod 信息、卷挂载等
rm -rf /var/lib/etcd/ # etcd 数据目录,存储集群状态数据
rm -rf /etc/cni/ # CNI 配置目录
rm -rf /opt/cni/ # CNI 插件目录- 这些目录包含了特定集群的配置和状态
- 如果不删除,新安装的 K8s 可能会使用旧的配置
- 可能导致新集群初始化失败或行为异常
- 特别是证书和 token 这类敏感信息需要清理
清理网络规则
# 清理 iptables 规则
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
# 清理 IPVS 规则
# 如果你的集群没有使用 IPVS 模式的 kube-proxy,就不需要清理 IPVS 规则
# 默认情况下,kube-proxy 使用的是 iptables 模式
# 如果你确实想安装 ipvsadm(通常不必要),请执行 dnf install -y ipvsadm
ipvsadm -C- K8s 会创建大量网络规则用于服务发现和负载均衡
- 这些规则如果不清理会影响新集群的网络功能
- 可能导致网络冲突或连接问题
- 特别是 Service 和 Pod 网络的路由规则需要清理
重启 containerd
systemctl restart containerd为什么不还原 containerd 配置
1.通用性(修改后的配置同样适用于 Docker,不会影响 Docker 的正常使用)
[plugins."io.containerd.grpc.v1.cri"]
systemd_cgroup = true # 这个配置对 Docker 也有益处2.性能考虑(优化后的配置对容器运行时性能有帮助)
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "runc" # 这是标准配置helm
Helm 是 Kubernetes 的包管理器,打开官网
安装helm
url https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash常用命令
搜索已添加的对应仓库名仓库
helm search repo 仓库keyword查看仓库中对应仓库名的所有版本
helm search repo 仓库keyword --versions搜索 Artifact Hub 的对应仓库名
helm search hub 仓库keyword查看 Artifact Hub 中对应仓库名的所有版本
helm search hub 仓库keyword --versions更新仓库
helm repo update查看已添加的仓库
helm repo list查看所有已经安装了的charts
helm list -A根据命名空间查询已经安装了的charts
helm list -n 仓库keyword通过helm安装kubernetes-dashboard
安装
# Add kubernetes-dashboard repository
helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
# Deploy a Helm Release named "kubernetes-dashboard" using the kubernetes-dashboard chart
helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
查看当前运行状态,待所有pod状态变为
Running即可
kubectl get pods -n kubernetes-dashboard -w
创建管理员用户
# 创建 admin-user.yaml
cat > admin-user.yaml <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
# 应用配置
kubectl apply -f admin-user.yaml获取访问令牌
# You can generate token for service account with: `kubectl -n NAMESPACE create token SERVICE_ACCOUNT`
kubectl -n kubernetes-dashboard create token admin-user
检查服务
kubectl get svc 是用来查看 Kubernetes 服务(Service)的命令,svc 是 service 的缩写
kubectl get svc -n kubernetes-dashboard
链接
方法一,修改服务类型为NodePort
注意
- 通过将 kubernetes-dashboard-kong-proxy 服务改为 NodePort 类型(端口范围:30000-32767),这样可以直接通过
节点 IP+分配的端口访问
修改 service 类型为 NodePort
#
kubectl patch svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard -p '{"spec": {"type": "NodePort"}}'
# 查看修改后的服务
kubectl get svc -n kubernetes-dashboard
查看分配的端口
kubectl get svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard
开启防火墙对应端口(如果执行过批量开启防火墙,则不需要执行这步,当然执行了也没问题)
# 开启 31399 端口
firewall-cmd --zone=public --add-port=31399/tcp --permanent
# 重新加载防火墙配置
firewall-cmd --reload
# 验证端口是否开启
firewall-cmd --list-ports还原配置
# 将 Service 类型从 NodePort 改回 ClusterIP
kubectl patch svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard -p '{"spec": {"type": "ClusterIP"}}'命令解释
- kubectl patch: 部分修改资源的命令
- svc: service 的缩写,表示要修改的资源类型是服务
- kubernetes-dashboard-kong-proxy: 服务的名称
- -n kubernetes-dashboard: 指定命名空间
- -p: patch 的缩写,后面跟着要修改的内容
- '{"spec": {"type": "ClusterIP"}}': JSON 格式的修改内容
- spec: 指定要修改的是规格部分
- type: 要修改的具体字段
- "ClusterIP": 新的值
关闭防火墙(根据自己情况判断是否需要关闭)
# 查看之前开启的端口
firewall-cmd --list-ports
# 关闭不需要的端口(假设是 31234)
firewall-cmd --zone=public --remove-port=31399/tcp --permanent
firewall-cmd --reload访问(注意是https协议)
https://10.2.7.56:31399一些可能会用到的命令
查看
使用 describe 命令查看
kubernetes-dashboard-kong-proxy的基本信息
kubectl describe svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard使用 get 命令加 -o yaml 参数查看的完整配置
kubectl get svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard -o yaml使用 get 命令加 -o json 参数以json格式查看
kubernetes-dashboard-kong-proxy的完整配置
kubectl get svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard -o json使用 get 命令加 -o wide 参数查看
kubernetes-dashboard-kong-proxy的更多列信息
kubectl get svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard -o wide修改
使用 edit 命令手动编辑
kubernetes-dashboard-kong-proxy配置(和使用vim的方式一样)
kubectl edit svc kubernetes-dashboard-kong-proxy -n kubernetes-dashboard注意事项
- 端口必须在 30000-32767 范围内
- 端口不能被其他服务占用
方法二,设置port-forward
通过port-forward(可以指定任意没有被占用的端口)
# 前台运行
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-kong-proxy 8443:443 --address 0.0.0.0
# 或者后台运行
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-kong-proxy 8443:443 --address 0.0.0.0 &该如何停止后台运的端口转发
方法一
直接关闭终端即可
方法二
如果执行的是上面的后台运行,可以用这个方法关闭
# 查找进程
ps aux | grep "port-forward"
# 使用 kill 命令终止进程(此处 PID 是 2178043)
kill 2178043
开启防火墙对应端口
# 开启 8443 端口
firewall-cmd --zone=public --add-port=8443/tcp --permanent
# 重新加载防火墙配置
firewall-cmd --reload
# 验证端口是否开启
firewall-cmd --list-ports访问(注意是https协议)
https://10.2.7.56:8443 填入令牌即可登录面板
填入令牌即可登录面板
界面如图所示
使用
资源创建方式:
- 命令行
- yaml
namespace
名称空间:用来对集群资源进行隔离划分。默认只隔离资源,不隔离网络
查看名称所有空间
简写为
ns,全拼为`namespaces
kubectl get ns命令行
创建命名空间
kubectl create ns 名字删除名称空间
删除名称空间时会将该名称空间下的资源连带删除
kubectl delete ns 名字yaml
创建命名空间
apiVersion: v1
kind: Namespace
metadata:
name: 名字根据
hello.yaml配置文件创建资源
kubectl apply -f hello.yaml删除名称空间
kubectl delete -f 名字.yamlpod
pod:运行中的一组容器,Pod是kubernetes中应用的最小单位.
查看所有pod
-A表示查看所有namespaces下的pod,不加-A则默认查出default名称空间下的pod
kubectl get pod -A查看pod的更多信息(多了ip、node、nominated node\readiness gates的信息)
# 这里可以写成-o wide,也可以写成-owide
kubectl get pod -o wide使用Pod的ip+pod里面运行容器的端口可以直接访问,这里的IP地址与之前初始化时指定的
--pod-network-cidr参数有关(集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod)
curl 10.244.0.17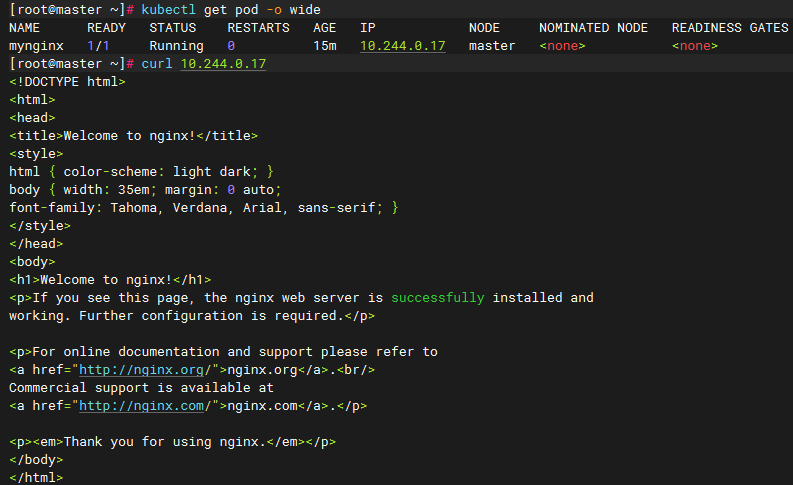
查看pod的描述信息
kubectl describe pod Pod名字进入pod
如果有两个容器,则默认会进入第一个容器
kubectl exec -it Pod名 -- /bin/bash使用
-c + 容器名指定进入的容器,此处为进入myapp这个pod中的tomcat容器里
kubectl exec -itc tomcat myapp -- /bin/bash命令行
创建一个pod
kubectl run mynginx --image=nginx删除pod
kubectl delete pod Pod名字查看Pod的运行日志
kubectl logs Pod名字yaml
创建一个只有一个容器的pod
pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: mynginx
name: mynginx
# namespace: default
spec:
containers:
- image: nginx
name: mynginx删除pod
kubectl delete -f pod.yaml创建一个有多个容器的pod
注意
如果pod中的容器都需要占用同一个端口,则会导致后启动的应用无法启动,k8s也会反复去启动该应用
multicontainer-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat运行
kubectl apply -f multicontainer-pod.yaml
访问nginx(80端口)
curl 10.244.0.20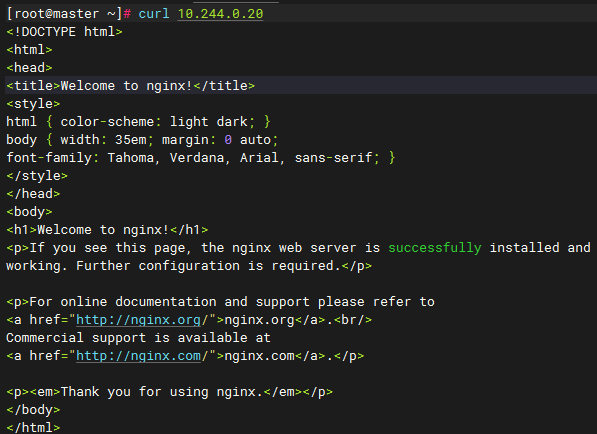
访问tomcat(8080端口)
curl 10.244.0.20:8080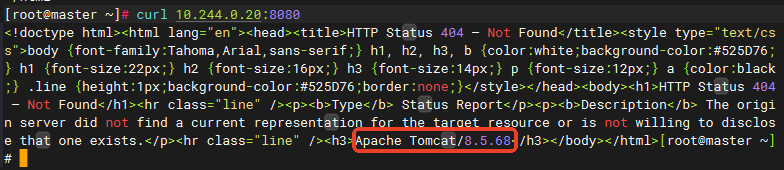
nginx访问tomcat
# 进入容器
kubectl exec -itc nginx myapp -- bash
# 访问tomcat
curl 127.0.0.1:8080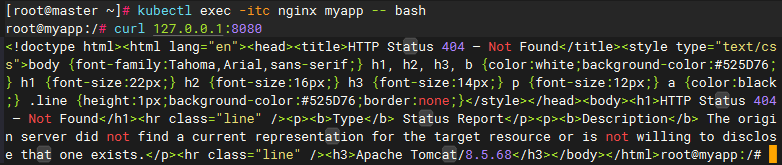
用kubernetes-dashboard编写yaml并部署
先切换到对应的名称空间(此处为default),编写完成后点击上传即可部署完成
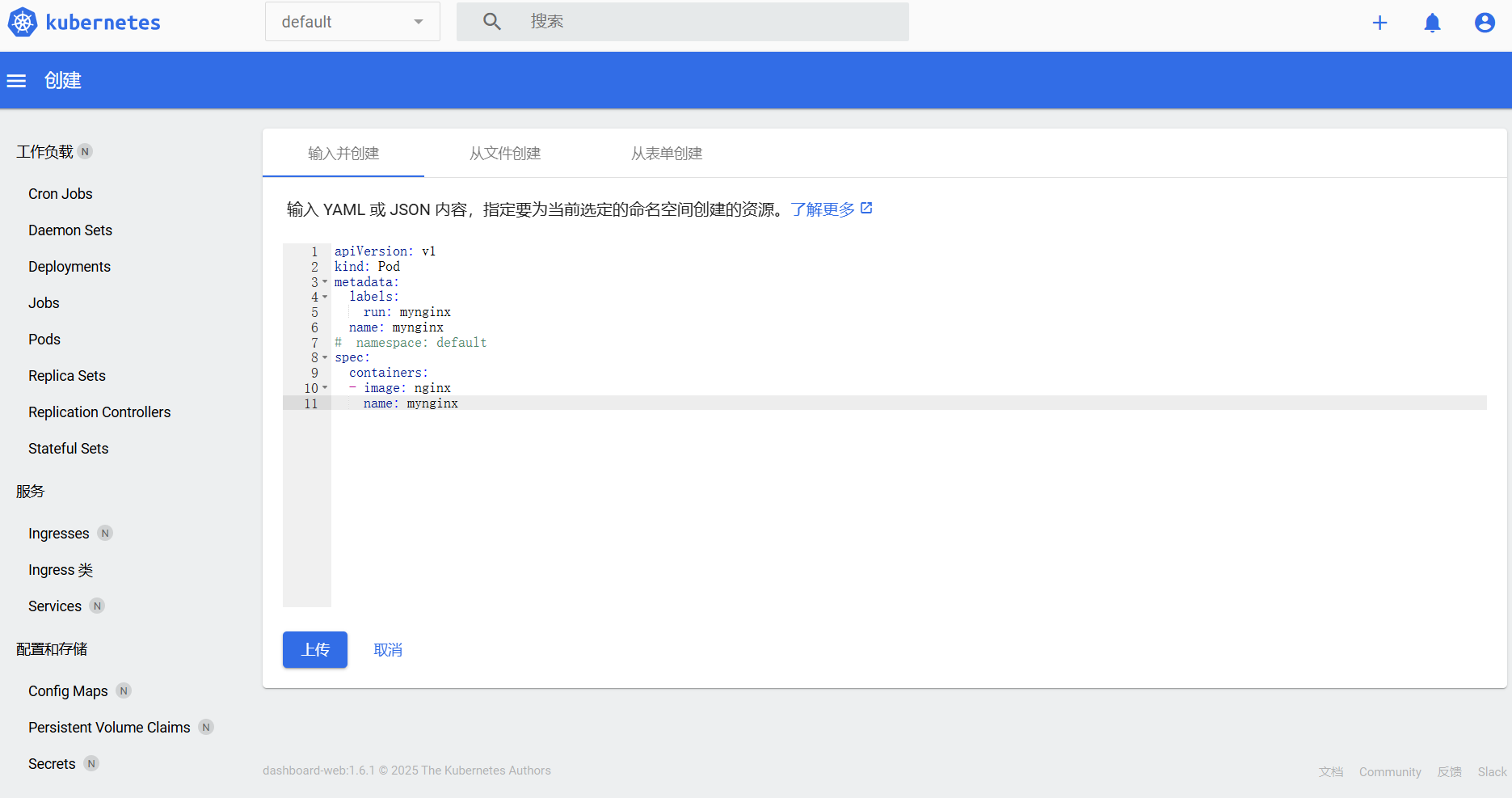
deployment
deployment:控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
查看deployment
这里的
deploy为简写
kubectl get deploy删除deployment
kubectl delete deploy deploy名使用deployment的好处
这里对比了两种创建pod的方式分别在删除pod后有什么效果
# 正常创建
kubectl run mynginx --image=nginx
# 使用部署创建
kubectl create deployment mytomcat --image=tomcat:8.5.68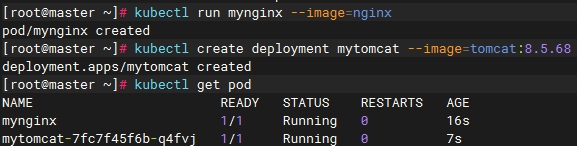
删除使用run命令部署的nginx
pod被直接删除了,没有被自动重新创建
kubectl delete pod mynginx
kubectl get pod
删除使用create deployment部署的tomcat应用
pod被直接删除了,但是又自动重新启动了一个tomcat容器,有自愈能力
kubectl get pod
kubectl delete pod mytomcat-7fc7f45f6b-q4fvj
kubectl get pod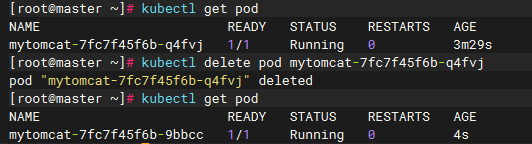
多副本
命令行
创建deployment
部署nginx,副本数量为3
kubectl create deploy my-dep --image nginx --replicas=3删除deployment
kubectl delete deploy my-depyaml
创建deployment
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginx部署
kubectl apply -f deployment.yaml删除deployment
可以指定配置文件删除
kubectl delete deploy -f deployment.yaml可以指定deploy名称删除
kubectl delete deploy my-dep扩缩容
可以使用的方式:
scale、edit
部署3个副本的nginx
kubectl create deploy my-dep --image nginx --replicas=3使用scale扩缩容
kubectl scale deploy deploy名 --replicas=副本数量扩容副本数量到5
kubectl scale deployment my-dep --replicas=5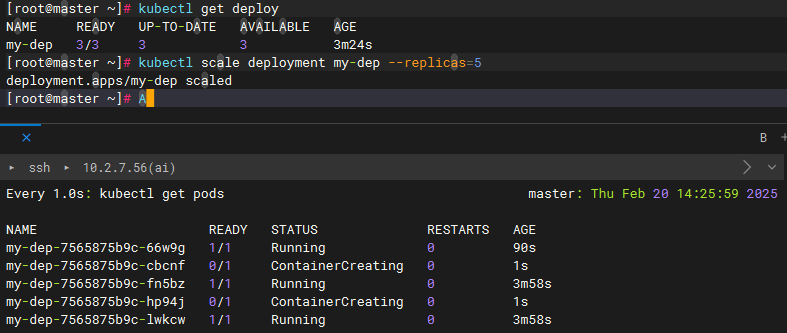
扩容完成

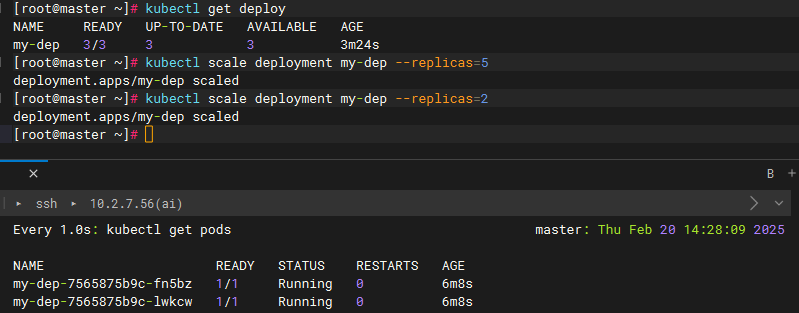
缩容副本数量到2
kubectl scale deployment my-dep --replicas=2缩容完成
使用edit扩缩容
使用
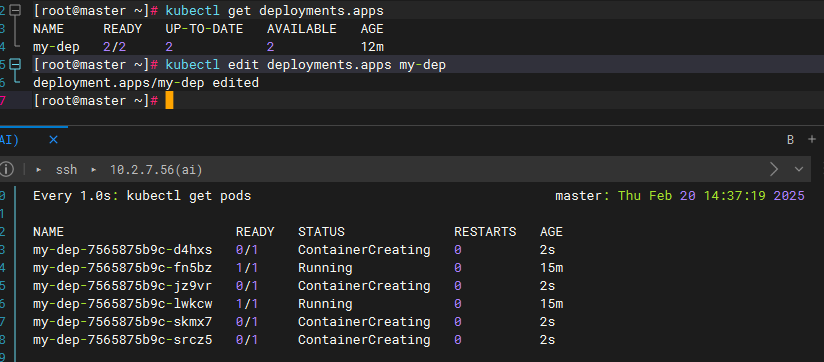
edit,直接编辑deploy的配置文件
kubectl edit deploy my-dep将
replicas改为想要的副本数量(此处为6)保存后会自动开始创建并运行副本
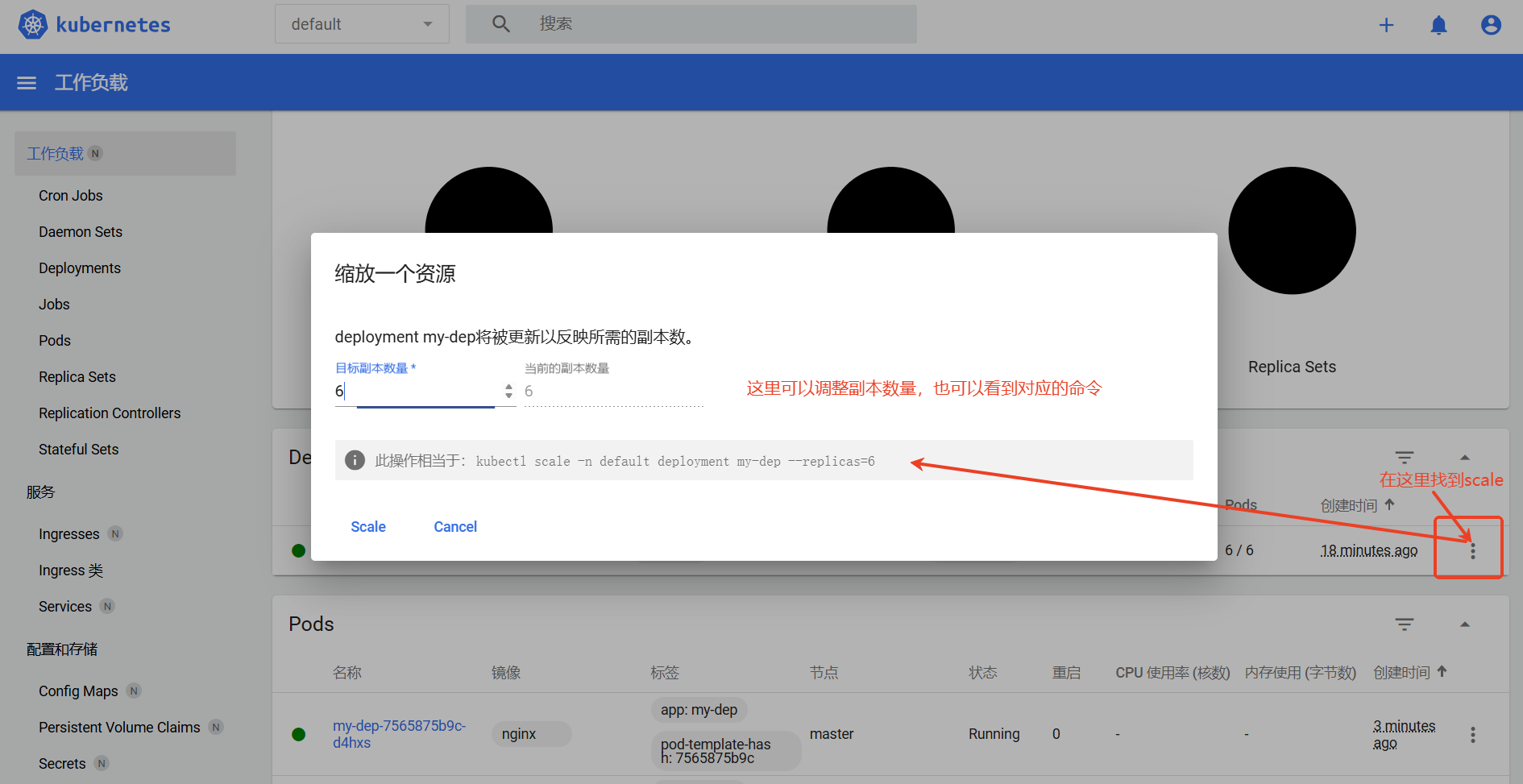
使用kubernetes-dashboard界面调整副本数量
自愈&故障转移
自愈:当pod在运行过程中崩溃了,k8s会自动重启pod。案例
故障转移:当运行pod的机器崩溃了、宕机、关机了,k8s在检测到之后(默认大概在5分钟左右会检测到)会将pod部署到其他机器上;案例待补充
滚动更新
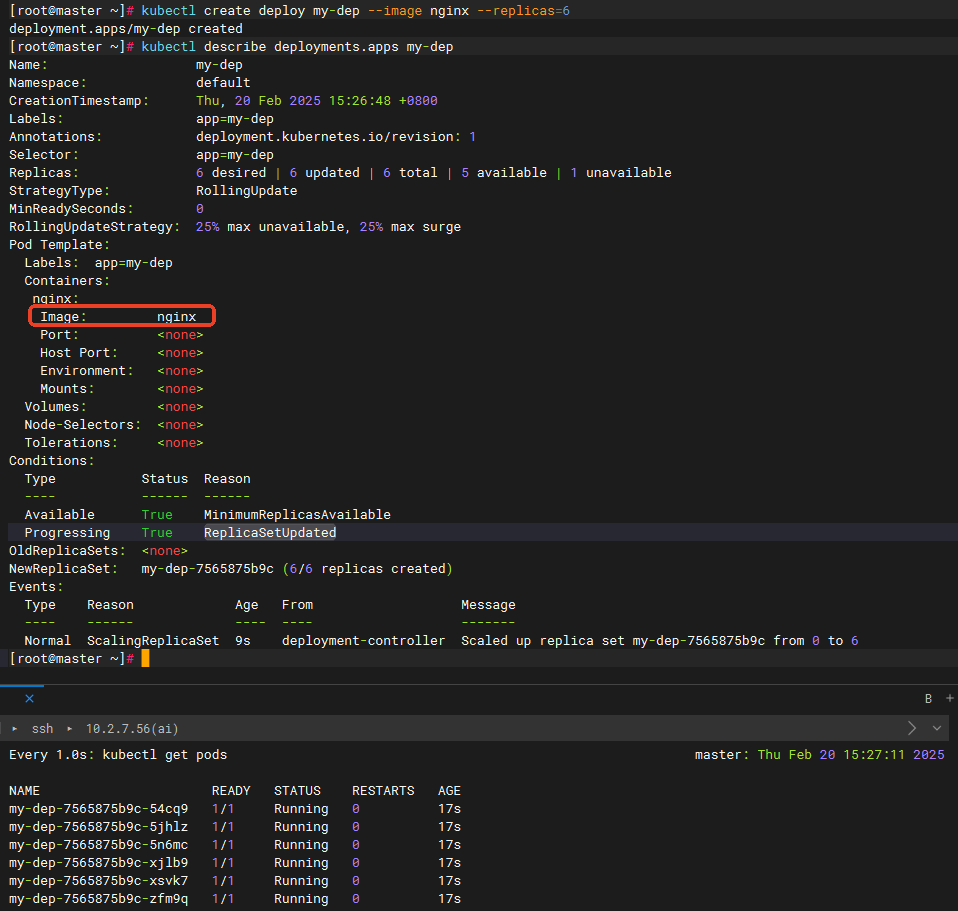
部署6个副本的nginx
kubectl create deploy my-dep --image nginx --replicas=6查看deploy的描述
kubectl describe deployments.apps my-dep此时的镜像为nginx
以yaml的方式查看当前的deploy
-oyaml表示以yaml格式打开(其他格式请用--help来查看)
kubectl get deployments.apps my-dep -oyaml将nginx镜像更新为nginx:alpine
注意:这里的--record已经过时了
kubectl set image deploy/my-dep nginx=nginx:alpine --record执行完命令后开始自动更新
更新完成后
查看描述信息
kubectl describe deployments.apps my-dep镜像成功更新为nginx:alpine

注意
--record:该参数用于标识变更记录,可以通过下面的这个语句查看变更记录,但是该参数已经过时了,现在可以通过annotate来设置记录
kubectl rollout history deployment/my-dep
还原一下试试
kubectl set image deployments my-dep nginx=nginxannotate写记录
添加变更说明
kubectl annotate deployment/my-dep kubernetes.io/change-cause="更新 nginx 镜像到最新版本"查看注解(可以直接用
describe命令在Annotations中查看)
kubectl describe deployment/my-dep | grep -i change-cause查看历史记录(历史记录可用于版本回退)
kubectl rollout history deployment/my-dep版本回退